
How Adaptive Retraining Impacts Historical Benchmarks
When predictive models are exposed to changing conditions, like injuries or market shifts, their accuracy can decline. Adaptive retraining helps models stay relevant by updating parameters with new data. This approach improves prediction accuracy but poses challenges for comparing results against historical benchmarks.
Key Takeaways:
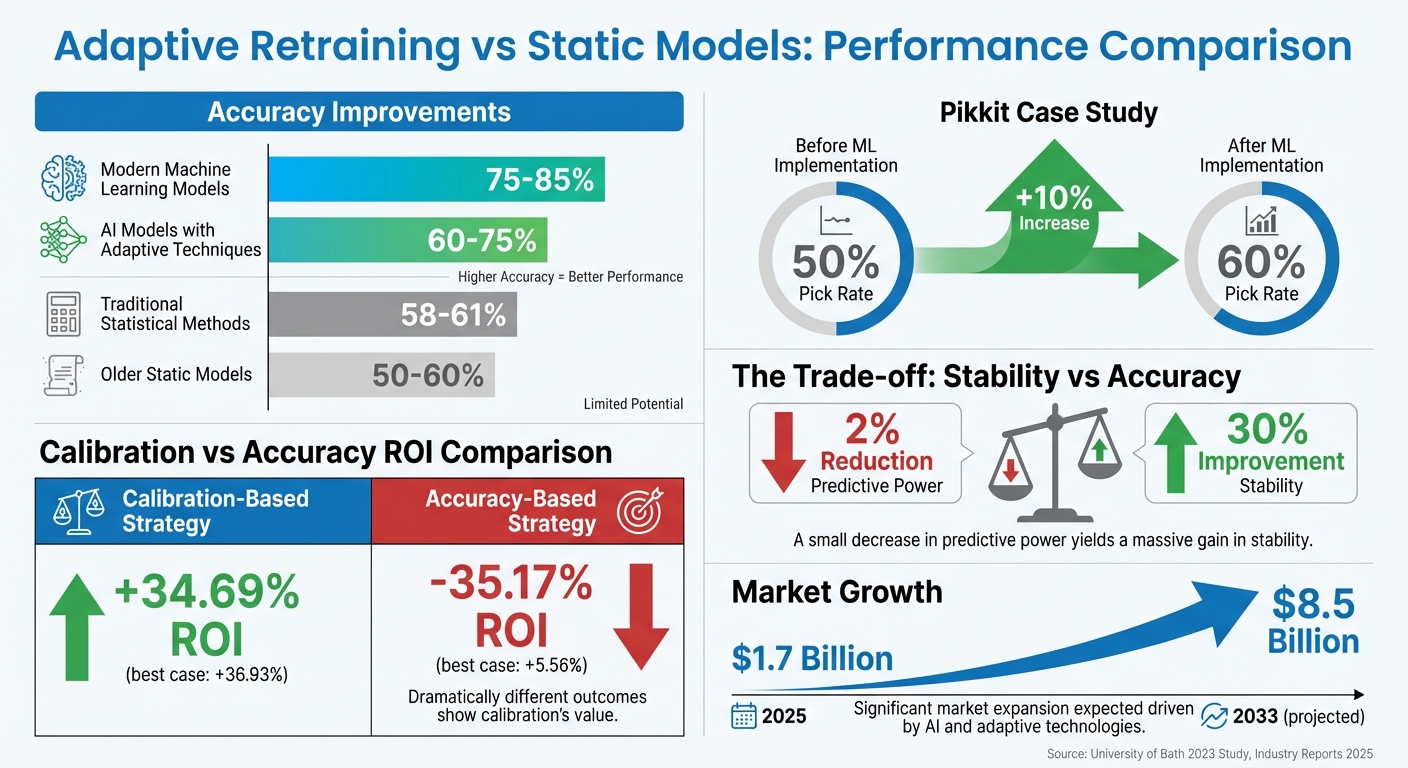
- Improved Accuracy: Models using adaptive retraining often outperform static models, achieving up to 75–85% accuracy in some cases.
- Challenges with Benchmarks: Traditional benchmarks struggle to account for evolving data, creating difficulties in measuring true performance.
- Sports Analytics Impact: Adaptive retraining ensures models remain effective in fast-changing environments like sports betting, where real-time events drastically influence outcomes.
- Validation Methods: Metrics like calibration and negative log-likelihood are critical for evaluating adaptive models, as they go beyond simple accuracy.
While adaptive retraining offers better predictions, it complicates comparisons with older benchmarks and requires thoughtful validation to avoid pitfalls like model collapse or overfitting.
How Adaptive Retraining Affects Historical Benchmarks
Adaptive vs Static Models: Accuracy Comparison in Sports Betting
This section dives into how adaptive retraining reshapes traditional historical benchmarks, building on its ability to improve predictive accuracy.
Performance Gains from Adaptive Retraining
Adaptive retraining stands out by constantly refining predictions, leading to better accuracy. For example, AI models that incorporate adaptive techniques typically achieve 60–75% accuracy in predicting game outcomes, compared to the 58–61% accuracy seen with traditional statistical methods. In some cases, modern machine learning models can predict game winners with 75–85% accuracy, a noticeable improvement over the 50–60% accuracy of older, static models.
The transition from static to dynamic modeling has fundamentally changed how predictions are made. Adaptive systems, leveraging reinforcement learning, adjust their weights after every new game outcome. This allows them to uncover patterns that static benchmarks or human analysts might overlook, such as public versus sharp betting splits or insights from social media sentiment.
A good example of this shift occurred in January 2026, when SportsLine's self-learning AI analyzed historical and current team data to produce numeric matchup scores and predictions for the NFL Wild Card Weekend. Its PickBot system reportedly made over 2,000 high-confidence prop picks since the 2023 season began. Similarly, DraftKings has integrated machine learning into its entire technical stack, from odds pricing to personalized app widgets, as of early 2026. These advancements, while impressive, make it harder to directly compare results with older benchmarks.
Difficulties in Benchmark Comparisons
While adaptive retraining offers clear performance benefits, it also introduces unique challenges for benchmarking. Static benchmarks often fail to account for environments where data evolves over time, which can lead to inaccurate assessments of a model's generalization error. This creates a "moving target" problem, where shifts in benchmarks make it difficult to measure true model performance.
Another issue is model collapse, where continuous test-time adaptation can cause a model to degrade over time, eventually performing worse than a static model due to error accumulation. In fact, asymptotic testing shows that most state-of-the-art test-time adaptation methods eventually underperform compared to simpler, non-adapting baselines. Research suggests that reducing predictive power by just 2% can lead to a 30% increase in model stability.
"A 2% reduction in predictive power leads to a 30% improvement in stability", explains Dimitris Bertsimas, Professor at MIT.
Additionally, traditional benchmarks don't account for the significant computational and human resource costs involved in retraining. These costs can sometimes outweigh the incremental accuracy improvements. For instance, generating reference ranges for an individual with 100 measurements using a Bayesian approach might take around 75 minutes, while an approximate algorithm can complete the same task in under a minute.
Real Examples: Adaptive Retraining in Sports Markets
In 2025, the social betting app Pikkit used machine learning to analyze betting trends, improving pick rates from 50% to 60%.
The market for AI-driven betting analytics is also expanding rapidly. By 2033, the industry is expected to grow from $1.7 billion in 2025 to $8.5 billion. Real-time odds adjustments have become almost instantaneous during live events, with AI recalculating odds in response to developments like red cards or injuries. Optimizing models for calibration rather than pure accuracy has been shown to deliver 69.86% higher average returns. These examples highlight how adaptive retraining is reshaping sports betting analytics, continuously redefining what benchmarks mean in this evolving field.
Methods for Validating Adaptive Retraining Against Benchmarks
To truly measure the impact of adaptive retraining, validation must go beyond surface-level metrics. It’s essential to examine calibration, accuracy, and real-time adaptability. The methods used will determine whether a model is genuinely improving or just appearing better on paper.
Calibration vs. Accuracy: The Balancing Act
Accuracy tells us how often predictions are correct, while calibration measures how reliable those predictions are. This distinction is especially critical in areas like sports betting. For instance, a model might correctly predict the winner of 70% of games, but if it assigns a 90% confidence level to those predictions, its overconfidence could lead to poor betting outcomes.
A 2023 study from the University of Bath highlights this trade-off. Researchers Conor Walsh and Alok Joshi trained machine learning models on NBA data and compared two betting strategies: one based on accuracy and another based on calibration using classwise-ECE. The calibration-focused approach achieved a +34.69% ROI over a season, while the accuracy-based method lost 35.17% of its bankroll. In the best-case scenario, calibration-based models reached +36.93% ROI, compared to just +5.56% for accuracy-based models.
"A highly accurate predictive model is useless as long as it coincides with the bookmaker's model", Walsh and Joshi noted.
While adaptive retraining can improve calibration, it’s not always for the right reasons. Trivial recalibration might adjust probabilities without genuinely improving predictions. That’s why validation should include metrics like negative log-likelihood (NLL), which captures both calibration and generalization, ensuring models don’t just game their scores.
| Metric | What It Measures | Risk in Adaptive Models |
|---|---|---|
| Accuracy | Proportion of correct predictions | Misses probability quality |
| Calibration | How well probabilities align with outcomes | Can be artificially improved |
| Negative Log-Likelihood | Combines calibration and generalization | Helps prevent metric manipulation |
These challenges underscore the importance of dynamic, real-time evaluation methods.
Real-Time Validation Methods
Static benchmarks often fall short in dynamic environments like sports betting, where conditions shift constantly. Real-time validation methods, such as adaptive rolling windows, provide a better way to measure performance. These windows update generalization error estimates as the environment changes, offering a more relevant evaluation than static historical data.
Periodic resets can also help. Techniques like RDumb, which resets periodically, often outperform complex adaptive algorithms by limiting error accumulation over time.
For models that need to adapt continuously, tools like Online Platt Scaling (OPS) recalibrate predictions during distribution shifts. Combining OPS with techniques like calibeating can further enhance robustness. Focusing updates on middle transformer blocks during retraining has also been shown to improve adaptability.
Ensuring Transparency in Model Evaluation
As models evolve, evaluation criteria must remain consistent and transparent. Clear metric definitions are essential to align adaptive retraining with historical benchmarks. One common pitfall is metric collapse, where a model over-optimizes for one goal - like calibration - at the expense of others. This trade-off can also limit how well a model can be interpreted.
The H-Bench framework addresses this by treating benchmarks as adaptive systems that incorporate both technical performance and stakeholder priorities. This approach allows benchmarks to evolve dynamically, balancing goals like minimizing false positives or reducing latency based on what matters most to users.
"Benchmarking itself must be democratized in such a way that human preferences are directly modeled and accounted for", explains Philip Waggoner from Stanford University.
Transparency also involves weighing different validation approaches. Refitting an entire model can eliminate drift but demands significant computational resources. On the other hand, recalibrating with a secondary model is faster but more prone to sampling errors. Choosing between these options is like managing a portfolio - balancing the speed of recalibration with the thoroughness of full model refitting.
How WagerProof Supports Adaptive Retraining and Benchmarking
Adaptive retraining and rigorous benchmarking gain their full potential when paired with accessible tools and reliable data. WagerProof bridges this gap by combining real-time sports data, clear analytics, and AI-driven insights, drawing on validation techniques commonly used in academic research. This blend of data and analytics directly supports the adaptive retraining strategies discussed earlier.
How WagerProof Identifies Value Bets and Outliers
Value bets emerge when a well-tuned model predicts odds that outperform the bookmaker's implied odds. WagerProof identifies these opportunities by comparing market spreads with its statistical models. When discrepancies arise - where the platform's data suggests odds that differ from the bookmaker's - users receive timely alerts.
The focus isn't just on picking winners but on creating models that assign accurate probabilities. WagerProof's Edge Finder tool embodies this approach, flagging games with a positive expected value based on probability mismatches. This transforms academic calibration concepts into actionable insights for bettors.
Access to Historical and Real-Time Data
Benchmarking requires both a historical perspective and live updates, and WagerProof provides both. The platform offers historical statistics alongside live data feeds, ensuring continuous performance evaluation. This setup helps avoid future data leakage - where models unintentionally train on events they haven’t yet seen. Keeping this separation intact is key to maintaining model relevance in a constantly changing data landscape.
WagerProof’s data pipeline processes information strictly in chronological order, ensuring predictions rely only on pre-game data. This mirrors the best practices of reinforcement learning with verifiable rewards (RLVR), where models are adjusted using on-policy training tied to objective outcomes, like actual game results. Users can track shifts in accuracy and calibration over time, making it easier to pinpoint when a model requires recalibration.
AI Analysis with WagerBot Chat
Timely model evaluation is critical, and WagerBot Chat offers instant analysis for bettors. By connecting to professional live data sources, WagerBot analyzes betting opportunities while avoiding common AI pitfalls. It uses proper scoring rules, such as the Brier score, to gauge the accuracy of forecasts, ensuring predictions remain reliable and well-calibrated. WagerBot also explains its recommendations, drawing on live stats, market movements, and contextual data.
This level of transparency is essential. As Conor Walsh and Alok Joshi from the University of Bath put it:
"A highly accurate predictive model is useless as long as it coincides with the bookmaker's model".
WagerBot empowers users to understand not just what to bet on, but why an edge exists - whether it’s due to public betting trends, outdated odds, or overlooked statistical inefficiencies.
Conclusion and Key Takeaways
Main Points on Adaptive Retraining
Adaptive retraining offers a way to refine model performance in the ever-changing world of sports betting markets, but it comes with its own set of challenges. One of its standout features is the idea of "embedded memory", which allows models to track long-term changes, such as shifts in team dynamics or market conditions, beyond typical context windows. However, this approach isn't without risks. As researchers Anmol Kabra and Kumar Kshitij Patel highlight:
"Naive retraining can be provably suboptimal even for simple distribution shifts".
This means that careless retraining can harm performance, especially when markets evolve in response to the model itself - a phenomenon known as the performativity trap. Interestingly, research shows that many advanced adaptation techniques falter over extended periods, sometimes performing worse than models that don't adapt at all. Surprisingly, simpler strategies, like resetting a model to its original pretrained state on a regular basis, often deliver better results. Calibration remains a key factor in ensuring stability and profitability in these markets.
The Future of Benchmarking in Adaptive Models
Static leaderboards are becoming a thing of the past, as dynamic benchmarking frameworks gain traction. These new frameworks, like the H-Bench, aim to incorporate human preferences into evaluation metrics, balancing technical performance with factors like error tolerance and interpretability. As Philip Waggoner from Stanford University puts it:
"Benchmarking itself must be democratized in such a way that human preferences are directly modeled and accounted for".
The future of benchmarking may lean on decision-theoretic approaches, treating model updates as portfolio optimization problems. This is especially relevant when the cost of retraining large-scale models can run into tens or even hundreds of thousands of dollars. Deciding between costly refitting to address data drift and more affordable recalibration becomes a strategic puzzle. Reinforcement learning is also emerging as a promising solution, enabling systems to allocate new data to specific model components. This helps prevent catastrophic forgetting while keeping computational demands in check. These adaptive approaches pave the way for practical applications, as seen in tools like those offered by WagerProof.
How WagerProof Helps Bettors Make Better Decisions
WagerProof applies these advanced concepts to help bettors navigate the complexities of adaptive retraining. Instead of offering opaque recommendations, the platform provides clear, data-driven tools. For instance, its Edge Finder tool identifies value bets by spotting mismatches between statistical models and bookmaker odds. By building on academic insights into calibration, it delivers actionable alerts that bettors can trust. The platform also ensures that both historical and real-time data are processed in the correct sequence, which is crucial for maintaining the integrity of model validation.
Another standout feature is WagerBot Chat, which connects to professional live data sources and uses proper scoring rules to keep predictions well-calibrated. This is vital because, as research points out:
"A highly accurate predictive model is useless as long as it coincides with the bookmaker's model".
FAQs
When should a model be retrained vs reset?
Retraining a model becomes necessary when its performance takes a hit due to data drift or distribution shifts - both of which can be identified by keeping an eye on monitoring metrics. If you notice a sharp decline in accuracy or if predictions start to feel unreliable, it's a clear sign that retraining should be on the table.
On the other hand, resetting a model might be the better option if accumulated errors lead to a breakdown in performance, where the model's ability to adapt becomes ineffective. While a reset provides a clean slate, it also comes with the downside of losing previously learned knowledge. Deciding between retraining and resetting ultimately hinges on monitoring results, the extent of data shifts, and weighing the costs and benefits of each approach.
How can you benchmark a model that keeps changing?
Benchmarking evolving models can be tricky since static benchmarks quickly become outdated. To tackle this, adaptive benchmarking frameworks offer a smarter approach. They continuously re-evaluate models using expanding datasets and cost-efficient methods like Sort & Search (S&S). By treating benchmarks as dynamic networks that evolve alongside models, we can ensure fair comparisons. This approach highlights ongoing improvements instead of relying on outdated, static snapshots, keeping evaluations relevant as models progress.
Which metrics outperform accuracy for betting models?
Metrics such as ROI (Return on Investment), log loss, calibration, and MAE (Mean Absolute Error) are more effective than accuracy when it comes to evaluating betting models. These metrics go beyond basic correctness, offering richer insights into areas like profitability, the reliability of predicted probabilities, and the magnitude of prediction errors. This makes them a more well-rounded choice for assessing how well a model performs in practical, real-world scenarios.
Related Blog Posts
Ready to bet smarter?
WagerProof uses real data and advanced analytics to help you make informed betting decisions. Get access to professional-grade predictions for NFL, College Football, and more.
Get Started Free