
Checklist for Using NLP in Betting
NLP (Natural Language Processing) can transform how you approach sports betting by analyzing unstructured text like tweets, news, and interviews to uncover trends, sentiment, and opportunities faster than manual research. Here's a quick rundown of what you need to know:
-
Why Use NLP in Betting?
- Saves time: Processes thousands of sources instantly vs. hours of manual research.
- Removes bias: Delivers data-driven insights without emotional influence.
- Scales effortlessly: Monitors hundreds of games and markets simultaneously.
-
How It Works:
- Tracks sentiment on social media and news to identify mood shifts around players or teams.
- Extracts odds and betting insights hidden in text (e.g., "Lakers are -2.5 favorites").
- Flags breaking news (like injuries) faster than sportsbooks adjust their lines.
-
Getting Started:
- Collect reliable data from APIs (e.g., Betfair, OddsPapi) or sources like Twitter and Reddit.
- Use tools like Python, spaCy, or Hugging Face for text processing.
- Clean and standardize data (e.g., normalize team names, remove unnecessary noise).
-
Maximize Insights:
- Combine NLP findings with structured data (e.g., odds and stats from WagerProof).
- Spot mismatches between public sentiment and market prices for value bets.
- Backtest your system with historical data to refine accuracy.
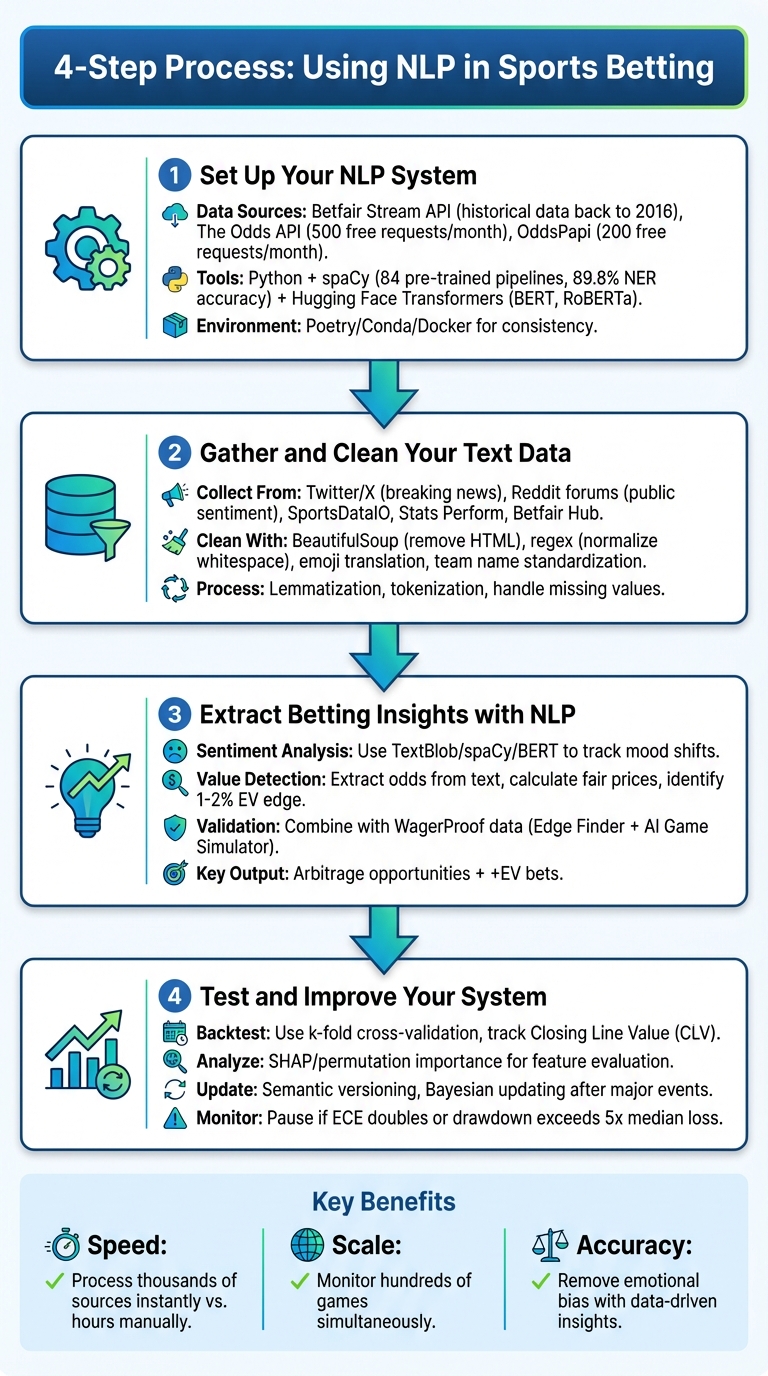
4-Step NLP Betting System Implementation Guide
Predicting Football Results and Beating the Bookies with Machine Learning
Step 1: Set Up Your NLP System
Getting started with extracting betting insights using NLP requires a solid foundation. This means pinpointing reliable data sources and equipping yourself with the right tools to process that data effectively. Without these essentials, even the most advanced models will struggle to deliver.
Find Quality Data Sources
The first step is locking down trustworthy data sources. Combine unstructured sports text data with structured odds data from APIs. This allows you to compare your NLP-driven insights against real-time betting lines.
For testing your models, historical data is a must. Betfair's Stream API is a great option, offering time-stamped odds as far back as 2016, with updates as frequent as every 50 milliseconds for pro-tier users. If you're on a budget, free tiers from providers like The Odds API (500 requests per month) or OddsPapi (200 requests per month) can help you get started. On the professional end, APIs from companies like Pinnacle and Circa aggregate data from hundreds of bookmakers, giving you access to true market prices - crucial for spotting mispriced lines at retail bookmakers.
"NLP helps bridge the gap between raw content and usable data. For odds scraping, this means gathering accurate, up-to-the-minute odds and betting insights from dozens of disparate sources - all in real time." - UnderdogChance
It’s worth noting that high-end providers like Sportradar charge upwards of $2,000 per month. To minimize costs, start with free or low-cost options and only scale up once your system starts generating consistent results. Also, when using APIs, be sure to implement caching (1–5 minutes) and exponential backoff strategies to avoid exceeding rate limits.
Select and Install NLP Tools
Python is the go-to language for building NLP systems in the betting space, thanks to its extensive AI libraries. A great starting point is spaCy, known for its speed and reliability. It supports over 75 languages and offers 84 pre-trained pipelines, making it a staple in the NLP industry since 2015. For cutting-edge capabilities, Hugging Face Transformers provides access to advanced pre-trained models.
For extracting deeper insights, tools like BERT (Bidirectional Encoder Representations from Transformers) and RoBERTa are excellent choices. These models are particularly adept at understanding sports-related content, allowing you to pull out key entities like player names or implied odds from complex text. To illustrate their reliability, the spaCy RoBERTa model achieved an impressive Named Entity Recognition accuracy of 89.8% on the OntoNotes 5.0 dataset.
You'll also need tools for managing your development environment, such as Poetry, Conda, or Docker, to ensure consistent results across different setups. Additionally, maintaining a team alias dictionary (e.g., mapping "Niners" to "49ers") is essential for normalizing data from multiple sources. This step helps prevent mismatches when combining information from varied datasets.
Step 2: Gather and Clean Your Text Data
Once your NLP system is ready, the next step is feeding it structured text data. But raw text often comes with its own set of challenges - abbreviations, slang, and inconsistent formatting can make it messy. Your task is to collect relevant sources and transform that chaos into clean, structured input that your models can actually work with.
Collect Text Data for Your Target Games
Now, it’s time to gather data from a variety of sources. Start with unstructured sources where valuable betting insights might be buried. For real-time updates, Twitter (X) is a goldmine. Whether it’s late-breaking injuries, last-minute quarterback changes, or coach commentary, this platform often reveals information before it affects betting lines. Similarly, Reddit sports forums and fan discussions can give you a sense of public sentiment - an early indicator of where the crowd is leaning.
For more structured options, professional services like SportsDataIO offer "News & Images" feeds, which even come with free trial access. Another option is Stats Perform, which provides "Facts and Insights" content tailored for predictive analysis. Meanwhile, the Betfair Hub can be scraped for historical tipster ratings and consensus prediction models.
Don’t overlook pre-game roster and injury news. This data is invaluable for betting, especially when your NLP model can automatically extract odds buried in phrases like, "The Lakers are slight -2.5 favorites". Integrating these insights is a core component of data-driven betting strategies that aim to outperform traditional bookmaker lines.
After gathering data, the next step is to clean and standardize it for reliable analysis, as data fixes common betting mistakes caused by messy or misinterpreted information.
Clean and Format Data for Analysis
Raw text is often cluttered with HTML tags, hashtags, and encoding errors that can inflate your vocabulary without adding any real value. Tools like BeautifulSoup and regex (e.g., re.sub(r"\s+", " ", text)) can help strip away HTML and normalize whitespace. Convert text to lowercase unless you’re working on Named Entity Recognition, and instead of deleting emojis, translate them into text (e.g., "🔥" becomes ":fire:"). Emojis can carry important sentiment cues, especially for market analysis.
Standardizing team names is another critical step. Create a mapping dictionary to ensure variations like "Tampa", "Tampa Bay", and "TampaBay" are all treated as the same entity. This prevents your model from misinterpreting them as different teams. For odds data, handle missing values like "NL" (No Line) by replacing them with numerical placeholders such as the median, ensuring your models can process the data smoothly.
Lemmatization is key for accuracy. By reducing words to their dictionary form (e.g., "ran" becomes "run"), you make it easier for your model to interpret sports commentary correctly. Libraries like spaCy or NLTK are great tools for tokenization, as they handle contractions and URLs more effectively than simple whitespace splitting.
"Text cleaning is signal engineering. You are not deleting data. You are clarifying intent." - Adekola Olawale
Step 3: Extract Betting Insights with NLP
NLP can transform clean text into actionable betting insights by uncovering sentiment changes, market gaps, and hidden opportunities. With your refined dataset from Step 2, follow these steps to extract and validate betting intelligence.
Track Sentiment and Identify Trends
Sentiment analysis helps you gauge the mood surrounding a team or player by analyzing platforms like social media, fan forums, and news headlines. Tools like Tweepy can scrape Twitter/X data, while TextBlob, spaCy, or BERT can assess sentiment polarity - whether the tone is positive or negative.
Pay attention to beat reporters for clues like "role shocks" or "rotation tells" in coach interviews, as these can influence player props before sportsbooks adjust lines. NLP can also analyze press conferences to reveal insights about team morale, strategies, or player readiness - details that raw stats might miss.
"Human analysts can be influenced by biases, emotions, or gut feelings. NLP-driven models... can analyze data without these cognitive biases." - Rarefiedtech
Look for mismatches between public sentiment and statistical probabilities. For instance, if social media overreacts to a star player's minor injury, but your NLP model detects speculative language rather than confirmed news, you might have found an opportunity.
Find Value Bets and Market Inefficiencies
NLP can automatically extract odds from text. For example, if an article mentions, "The Lakers are slight -2.5 favorites", your model can log that line and compare it across numerous sources. This helps identify price mismatches between sportsbooks, a process known as arbitrage detection.
You can also calculate a "fair" price by averaging no-vig probabilities from multiple sportsbooks. Compare this consensus price to the best available odds to find bets with positive expected value (+EV). For major markets, aim for at least a 1%–2% EV edge when combining NLP insights with consensus prices.
"Winning long-term isn't about 'hot picks.' It's about price. If you can routinely buy +110 when the fair price is +102, you're capturing positive expected value (EV)." - Betpera
Set up alerts for NLP-detected news - like a key player injury or sudden weather change - that creates a gap between public opinion and current betting odds.
Combine NLP with WagerProof Data
Once you've identified potential value bets using NLP, validate them with WagerProof data for precision. NLP offers "soft" signals like locker room dynamics or subtle injury updates, while WagerProof provides "hard" market validation through line movement and implied probabilities. Use WagerProof's Edge Finder to confirm whether market odds have adjusted to the news flagged by your NLP analysis.
For example, if NLP detects a shift in sentiment about a quarterback's minor injury, feed this insight into WagerProof's AI Game Simulator to simulate thousands of scenarios and assess how win probabilities change. You can also use WagerBot Chat to explore how NLP-detected news - such as a weather shift - might impact historical performance data in WagerProof's database.
By combining real-time NLP signals with WagerProof's transparent analytics, you can quickly verify news outliers and identify arbitrage or high-EV opportunities. WagerProof's multi-model consensus approach removes uncertainty by showing the math behind its insights, helping you ensure your NLP findings align with broader market trends.
| Factor | NLP Analysis | WagerProof Data |
|---|---|---|
| Strengths | Finds hidden context (e.g., morale, tactics) | Real-time speed & precise math |
| Weaknesses | High noise; language ambiguity | May lack nuanced "human" context |
This hybrid approach - using NLP for large-scale data processing and WagerProof for precise validation - provides a well-rounded view. Together, these tools ensure your decisions are backed by both qualitative insights and quantitative accuracy, building on the groundwork laid in earlier steps.
Step 4: Test and Improve Your System
Testing and making regular updates are crucial as team dynamics and market conditions shift over time.
Backtest Your Models with Past Data
Run your NLP model against historical game data to evaluate how it would have performed. Use techniques like splitting your dataset into training and testing sets or applying k-fold cross-validation to measure how well the model handles unseen data. This helps you determine whether your model is identifying meaningful patterns or just memorizing random noise.
A key metric to track is Closing Line Value (CLV). If your model consistently spots bets with better odds than the final closing line, it’s a strong signal that you’re outperforming the sharpest market prices - a reliable indicator of long-term profitability.
To understand your model’s decision-making, use tools like SHAP or permutation importance. They can reveal which features have the most influence on your model’s predictions. For instance, if your NLP analysis highlights sentiment terms like "questionable" or "game-time decision", these tools can show whether such keywords genuinely correlate with profitable bets or simply add unnecessary complexity.
Once backtesting confirms your model is dependable, make it a habit to update your system regularly to keep it aligned with fresh data and market changes.
Update Your Models with New Data
To stay ahead, your models need to evolve alongside roster changes, coaching shifts, and even the way language is used in reporting. NLP models are particularly sensitive to such changes. A model that excelled last season might struggle to deliver accurate predictions this year. As UnderdogChance explains:
"A model that was well-calibrated last season might fall apart this year. The key is continuous calibration".
When updating your models, use semantic versioning and maintain a detailed changelog. Log everything - from raw data sources and acquisition dates to the specific cleaning steps used. This ensures your new data remains consistent with your original training set. After major in-game events, apply Bayesian updating to fine-tune probabilities. If your live model’s Expected Calibration Error (ECE) doubles the target or session drawdown exceeds five times the median loss, consider pausing the system for adjustments.
Reassess feature importance regularly to ensure that variables like sentiment spikes or specific reporter language still add value. Markets change, and your model needs to adapt to remain effective.
Conclusion: Better Betting Decisions with NLP
Incorporating NLP into your betting routine allows you to uncover insights from sources like news, social media, and interviews - details that traditional stats alone might overlook. By setting up a systematic workflow that includes data cleaning, extraction, and testing, you’ve created a solid foundation for spotting betting opportunities ahead of market shifts.
This guide has outlined a complete workflow, showing how its components come together to improve decision-making. The real advantage lies in combining NLP-driven insights with structured, professional data sources. NLP excels at processing unstructured information, such as sentiment analysis and breaking news in real time. Meanwhile, platforms like WagerProof provide structured data, including prediction markets, historical stats, public betting trends, and statistical models for validation.
| Feature | NLP Insights | WagerProof Pro Data | Combined Benefit |
|---|---|---|---|
| Data Type | Unstructured (News, Tweets) | Structured (Stats, Odds) | Holistic view of game conditions |
| Primary Use | Sentiment & Trend Detection | Probability & Value Calculation | Identification of +EV opportunities |
| Speed | Real-time news processing | Real-time market monitoring | Faster reaction to line movements |
| Risk Management | Reduces cognitive bias | Offers statistical calibration | Objective, data-driven decision-making |
The key is to adopt a hybrid strategy: let automated NLP tools handle massive amounts of unstructured data, while WagerProof’s AI Game Simulator and Edge Finder validate high-value opportunities. This approach ensures both speed and accuracy, transforming thousands of data points into actionable value bets based on evidence - not intuition.
Leverage WagerProof’s tools to combine your NLP findings with professional-grade data, and take your betting decisions to the next level.
FAQs
What’s the simplest NLP setup I can start with?
The most straightforward way to dive into natural language processing (NLP) is by using basic text analysis to uncover insights from sources like news articles or social media. Here's how you can get started:
- Gather Relevant Text Data: Collect information from platforms or publications that align with your betting interests, such as sports updates or expert opinions.
-
Apply Simple Techniques: Start with foundational methods like:
- Tokenization: Breaking text into individual words or phrases.
- Filtering: Removing irrelevant words or stop words (like "and" or "the").
- Keyword Searches: Identifying specific terms or phrases related to your focus area.
Once you're comfortable with these basics, you can gradually move into more advanced approaches, such as creating custom features or working with word vectors. Starting simple is a practical way to introduce NLP into your betting strategy while building your skills along the way.
How do I turn sentiment into a betting signal?
To harness sentiment as a betting signal using NLP, start by analyzing unstructured data sources such as news articles, social media posts, and expert commentary. These tools can measure public or expert opinions by quantifying sentiment trends. The resulting sentiment scores can then be integrated into predictive models, offering insights into potential shifts in game outcomes or odds. This process can uncover actionable betting opportunities and highlight potential risks.
How can WagerProof validate my NLP alerts fast?
WagerProof makes validating your NLP alerts fast and efficient by leveraging real-time data tools. Features like the Edge Finder and live insights help pinpoint outliers and uncover value bets by identifying gaps between your predictions and market odds. On top of that, WagerProof tracks crucial metrics like Closing Line Value (CLV) and calibration, automating the analysis of your performance. This means your alerts are backed by reliable, actionable data for smarter decision-making.
Related Blog Posts
Ready to bet smarter?
WagerProof uses real data and advanced analytics to help you make informed betting decisions. Get access to professional-grade predictions for NFL, College Football, and more.
Get Started Free