
Top 5 Classification Models for Match Predictions
Classification models are key tools for predicting sports match outcomes like wins, losses, or draws. They analyze historical and real-time data to provide actionable insights for bettors. Here's a quick breakdown of the five most effective models for match predictions:
- Logistic Regression: Simple, transparent, and effective for binary outcomes (e.g., win/loss). Works well with smaller datasets but requires adjustments for multiclass problems like soccer.
- Decision Trees & Random Forests: Decision trees offer clear predictions, while random forests improve accuracy by combining multiple trees, reducing overfitting.
- Support Vector Machines (SVMs): Great for high-dimensional data and complex relationships but less interpretable compared to simpler models.
- Neural Networks: Handle non-linear patterns and large datasets, achieving high accuracy but often criticized for being a "black box."
- Gradient Boosting Machines (e.g., XGBoost): Excel with smaller datasets and iterative learning, offering high accuracy and probability calibration.
Each model has strengths tailored to specific sports and data types. Combining them often yields the best results, especially for identifying value bets where sportsbook odds and predictions differ. Platforms like WagerProof leverage these models to enhance betting strategies with tools like the Edge Finder and AI Game Simulator.
Quick Comparison:
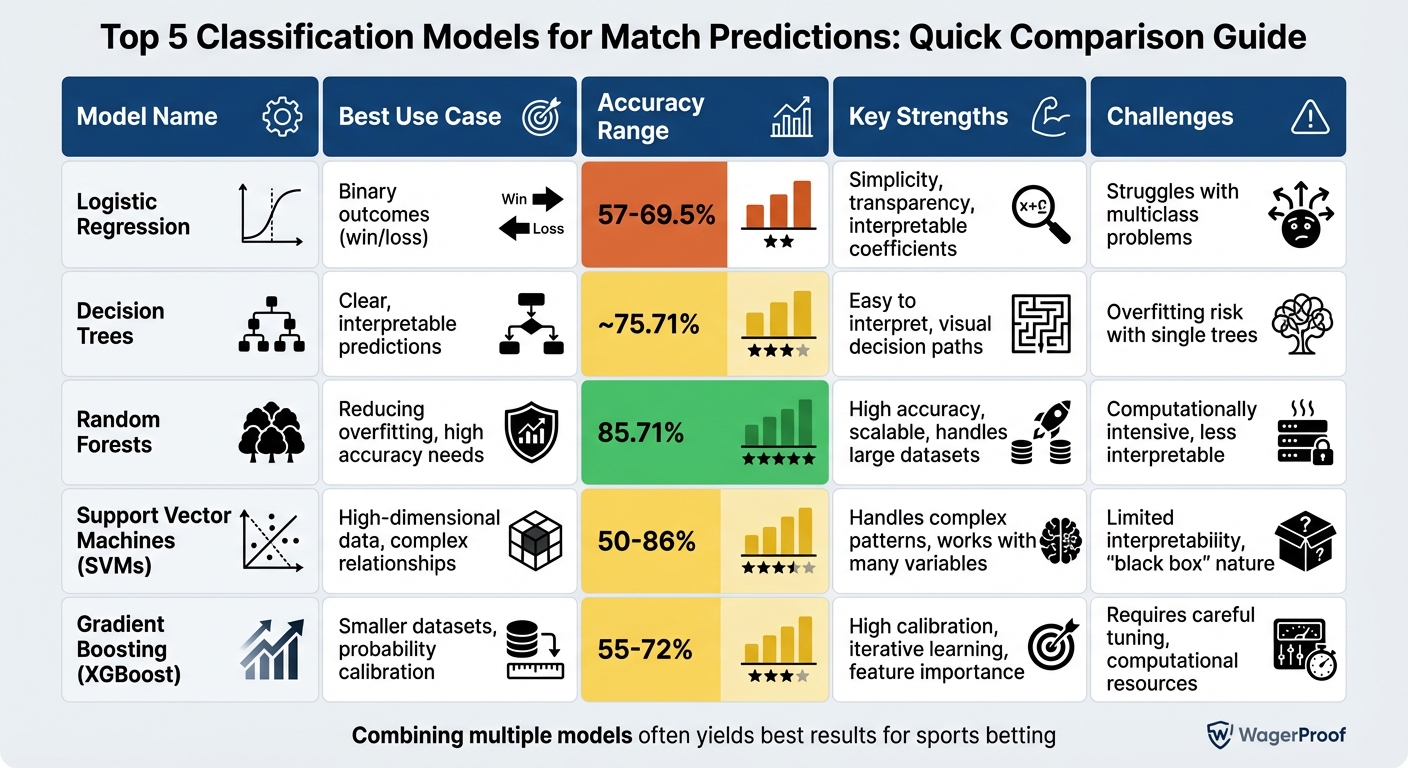
| Model | Best Use Case | Accuracy Range | Key Strengths | Challenges |
|---|---|---|---|---|
| Logistic Regression | Binary outcomes | ~57-69.5% | Simplicity, transparency | Struggles with multiclass |
| Decision Trees | Clear predictions | ~75.71% | Easy to interpret | Overfitting risk |
| Random Forests | Reducing overfitting | ~85.71% | High accuracy, scalable | Computationally intensive |
| SVMs | High-dimensional data | ~50-86% | Handles complex relationships | Limited interpretability |
| Gradient Boosting (XGBoost) | Smaller datasets | ~55-72% | High calibration, iterative learning | Requires tuning |
These models are the foundation of modern sports analytics, helping bettors make informed, data-driven decisions.
Classification Models for Sports Betting: Performance Comparison Chart
Process to Build a Sports Betting Model End to End
1. Logistic Regression
Logistic regression is a widely-used model in sports predictions, particularly for its ability to predict binary outcomes - like a win or loss - based on team and player statistics. What sets it apart is its simplicity and clarity. Unlike more complex models that can feel like a "black box", logistic regression lays out its predictors clearly through coefficients. This transparency makes it a favorite in sports betting analytics.
Performance on Sports Data
The performance of logistic regression varies depending on the sport and the data used. For instance, an NFL study analyzing data from 2017 to 2019 achieved 57% accuracy by leveraging rolling averages and fine-tuning hyperparameters - just slightly better than the home-win baseline of 56%. In a different case, researchers used logistic regression to predict the 2015/2016 Barclays Premier League season, achieving 69.5% accuracy by incorporating home/away offensive and defensive metrics along with FIFA data. These examples underscore an important point: the choice of features and the unique dynamics of each sport often matter more than the model itself.
Interpretability and Transparency
"Logistic regression is a classification method which can be used to predict sports results and it can gives additional knowledge through regression coefficients." - IEEE Conference Publication
One of logistic regression's biggest strengths is its transparency. The model provides interpretability through odds ratios, which quantify how a single unit change - such as one more assist or turnover - affects the probability of a win. For coaches and analysts, this clarity is invaluable, as it helps explain why a prediction was made. Unlike more opaque models, logistic regression offers insights that are easy to communicate and understand.
"The model's interpretability and effectiveness in handling binary outcomes make it a powerful tool in decision-making processes. It also facilitates transparency, allowing analysts to communicate insights to stakeholders in a clear and concise manner." - Sarah Lee, AI analyst
This level of interpretability makes logistic regression an essential tool, especially for real-time decision-making in sports betting and analysis.
Suitability for Sports-Specific Applications
Logistic regression shines in binary win/loss scenarios, making it particularly effective for leagues like the NFL and NBA. It’s computationally efficient and works reliably even with smaller datasets. However, when applied to soccer, where outcomes often include draws, multinomial logistic regression becomes necessary. This adaptation allows the model to handle three-way outcomes (win, draw, loss), which is critical since 66.2% of soccer matches end in either a draw or a one-goal difference.
The model also performs well in identifying value bets by comparing predicted probabilities against sportsbook odds. Additionally, it’s useful for providing real-time win probability updates during games, offering actionable insights for bettors and analysts alike.
2. Decision Trees and Random Forests
Building on predictive models like logistic regression, decision trees and random forests offer a different way to make accurate predictions. A decision tree works by making sequential decisions based on team statistics, while random forests take it further by combining multiple decision trees. This combination creates a more reliable and consistent forecast. Let’s dive into how these models perform when applied to sports data.
Performance on Sports Data
The gap in performance between these two models can be striking. Researchers Yuanzhen Ni and Seongno Lee from Hanyang University studied 354 NCAA basketball teams over five seasons (2015–2019). They found that a single decision tree reached 75.71% accuracy, but it struggled with overfitting. Switching to a random forest model boosted accuracy to 85.71%. The improvement comes from the random forest's ability to reduce variance by averaging predictions from multiple trees, a technique known as bagging.
For NFL predictions, developer C. Woo tested a random forest classifier using boxscore data from the 2017–2019 seasons. The model achieved 58% accuracy and a 63% F1-score, slightly outperforming logistic regression (57% accuracy) but falling short of XGBoost (60% accuracy). In MLB, random forests were used to predict batter hits, achieving a 61% precision rate. Feature engineering played a big role here - using rolling averages from recent games provided better results than relying on season-long stats.
Interpretability and Transparency
One of the standout features of decision trees is their ability to clearly explain why a prediction was made. Unlike more complex algorithms, they visually outline decision points, such as identifying when a team's defensive rating surpasses a certain threshold while the opposing team’s offensive efficiency remains low. Random forests, while more complex, still retain some of this transparency. They can highlight which variables are most influential in predictions, whether it’s pitcher stats versus batter performance in baseball or specific matchup details in football.
Scalability with Large Datasets
Random forests are particularly well-suited for handling large datasets. For example, they’ve been used to analyze data from over 302,691 historical soccer matches spanning 51 leagues and 23 years. Automated systems can process live data and simultaneously analyze more than 50 games. This scalability makes random forests a practical choice for real-time applications, such as sports betting, where markets can shift in an instant.
3. Support Vector Machines (SVMs)
Support Vector Machines (SVMs) offer a flexible, non-parametric approach that often outperforms traditional algorithms like logistic regression when tackling complex relationships. This makes them particularly effective for analyzing intricate connections in player statistics, team dynamics, and other influencing factors.
Performance on Sports Data
SVMs deliver results that vary depending on the context. For instance, a December 2023 study by Yuanzhen Ni and Seongno Lee from Hanyang University examined data from 354 NCAA basketball teams spanning five seasons (2015–2019). In their research, random forests achieved an impressive 85.71% prediction accuracy, while SVMs performed slightly below that benchmark. However, for binary classification tasks, SVMs using a linear kernel showed strong results, achieving 86.12% accuracy and 78.31% precision, outperforming logistic regression's 73.33% accuracy. In Greek Super League soccer predictions, SVMs were part of the analytical toolkit, though CatBoost emerged as the top performer. Generally, SVM models achieve prediction accuracies between 50% and 60% in real-world betting scenarios.
Interpretability and Transparency
One common critique of SVMs is their reputation as "black boxes." Unlike decision trees, which clearly outline their decision-making process, SVMs operate in ways that are harder to interpret. This lack of transparency can make it challenging to understand the reasoning behind specific predictions. To address this, efforts to reveal the data and signals driving the model's decisions can help make SVM-based predictions feel more reliable and trustworthy.
Scalability with Large Datasets
SVMs shine when processing large datasets, efficiently handling thousands of variables, such as weather conditions, referee tendencies, travel schedules, and historical matchups. This ability makes them ideal for real-time applications, like generating alerts in high-stakes betting scenarios. However, as datasets grow increasingly large or complex, ensemble models like random forests or gradient boosting machines often deliver better performance.
Despite these challenges, SVMs remain a powerful tool in high-dimensional data scenarios, complementing other classification methods.
Suitability for Sports-Specific Applications
SVMs are particularly effective in sports analytics due to their ability to handle high-dimensional data without requiring extensive feature engineering. For example, in soccer - where 66.2% of matches end in either a draw or a one-goal margin - accurate classification is critical. SVMs are frequently used to predict outcomes like home win, draw, or away win in leagues such as the NFL, NBA, and various soccer competitions. Combining SVMs with other models in multi-model strategies often improves both reliability and objectivity.
These insights into SVM performance and scalability pave the way for exploring even more advanced models, such as Neural Networks.
4. Neural Networks
Neural networks are particularly adept at identifying the intricate, non-linear relationships present in team sports. For example, they can analyze how factors like a player's speed and stamina interact to impact game outcomes.
Performance on Sports Data
When it comes to predicting game winners, neural networks deliver 75–85% accuracy across major sports - a considerable leap from traditional statistical models, which often hover around 50–60% accuracy. This performance edge isn't just theoretical. In competitive forecasting challenges, neural networks consistently rank among the top-performing tools. A study using NBA data revealed an interesting insight: models selected for their calibration achieved an average ROI of +34.69%, while those chosen purely for accuracy resulted in a −35.17% ROI.
"For sports betting (or any probabilistic decision-making problem), calibration is a more important metric than accuracy." - Conor Walsh, Researcher
Interpretability and Transparency
Despite their strong performance, neural networks are often criticized for their lack of transparency. Unlike decision trees, which clearly outline their decision-making process, neural networks are often referred to as a "black box". This opacity can make users uneasy, especially when they don't understand why a model suggests a particular bet. To address this, platforms like WagerProof employ multi-model consensus approaches. By running multiple analytical models in parallel and highlighting areas of agreement, they create predictions that are easier to trust and backed by rigorous mathematical reasoning.
Scalability with Large Datasets
One of the standout features of neural networks is their ability to process massive datasets in real time. These models can analyze thousands of data points simultaneously, including player tracking stats, weather conditions, injury updates, referee tendencies, and historical matchups. This scalability becomes especially crucial during high-stakes periods like NFL Sundays or March Madness, when dozens of games are happening at once. For micro-betting markets, which require precise play-by-play predictions, neural networks can boost accuracy from 10–20% to over 40%. Such capabilities pave the way for even more advanced approaches, such as ensemble methods, which will be explored later.
Suitability for Sports-Specific Applications
Neural networks excel at adapting to the unique demands of different sports. In soccer, they effectively handle interdependent time series data, capturing how teams influence each other’s performance over time. For NFL and NBA applications, they process a wide range of inputs - everything from social media sentiment and real-time player tracking to historical stats - uncovering patterns that simpler models often overlook. The secret lies in feature engineering, which involves breaking down performance data into "total", "home", and "away" views to account for venue-specific trends.
Platforms like WagerProof combine neural network outputs with other model predictions to create a seamless toolkit for real-time sports betting. Their Premium plan leverages these neural network capabilities through tools like the AI Game Simulator and WagerBot Chat, delivering live predictions powered by professional-grade data.
5. Gradient Boosting Machines (e.g., XGBoost)
Gradient boosting machines, including XGBoost, CatBoost, and LightGBM, are among the top-performing models for predicting sports outcomes. These models work by refining decision trees in a step-by-step process to minimize errors, making them excellent at handling the complex, non-linear patterns often found in sports data. Unlike deep learning models, which usually require massive datasets, gradient boosting models excel with the smaller, season-specific datasets typical in sports leagues. Their ability to iteratively improve predictions makes them a standout option for sports analytics.
Performance on Sports Data
Gradient boosting models consistently deliver better results than traditional methods across various sports. For example, in the NFL, XGBoost has achieved an accuracy of 60%, while NBA predictions range between 67% and 72%. Soccer, with its frequent draws and low-scoring nature, poses a tougher challenge. However, by combining CatBoost with pi-ratings, a post-competition accuracy of 55.82% was achieved, along with a Ranked Probability Score of 0.1925.
What truly sets the best models apart isn’t just raw accuracy - it’s calibration. Calibration measures how closely predicted probabilities align with actual outcomes, which is essential for sports betting. In this context, having precise probability estimates is often more valuable than simply predicting wins or losses.
"Gradient-boosted tree models... are currently able to achieve some of the highest performance." - Alex Marin Felices, Data Scientist, The xG Football Club
Interpretability and Transparency
Although often considered "black box" models, gradient boosting machines provide insights through SHAP values. This method highlights which features - such as passing efficiency, defensive rebounds, or home-field advantage - played the most significant role in a prediction. For coaches and analysts, this means the models don’t just reveal what might happen but also why it’s likely to happen. The success of these models often lies in their use of domain-specific metrics like Elo ratings or pi-ratings, rather than relying solely on raw statistics, to capture the subtle dynamics of real games.
Scalability with Large Datasets
XGBoost is designed to handle large-scale data efficiently. It supports parallel tree boosting and integrates with distributed systems like Hadoop and Spark, making it capable of processing billions of data points. With GPU acceleration, training times are significantly reduced. For instance, in NFL win probability modeling, XGBoost processed play-by-play data from entire seasons and achieved approximately 80% test accuracy. This level of computational efficiency is especially valuable during busy periods when multiple games occur simultaneously, requiring real-time predictions.
Tailored Applications for Different Sports
Each sport poses unique challenges, and gradient boosting models adapt impressively to these differences. In the NFL, where structured plays and home-field advantages are prominent, these models achieve 65–70% accuracy. For basketball, they handle high-dimensional data such as player tracking stats and individual impact metrics, reaching an accuracy range of 67–72%. Soccer, with its unpredictable nature and low scoring, remains the most difficult to predict. Even so, when applied to specialized rating systems, gradient boosting models outperform alternatives, delivering 55–65% accuracy.
Platforms like WagerProof combine gradient boosting outputs with neural networks and other models to create a multi-layered approach. This integration helps identify value bets and anomalies in real time, offering users the same advanced tools used by professionals to refine sports betting strategies.
How WagerProof Uses Classification Models

WagerProof taps into the power of classification models to deliver insightful, data-driven betting guidance. By combining predictions from various models - like logistic regression, neural networks, and gradient boosting - it reduces the risk of errors from any single model. This blend of approaches ensures more accurate and dependable real-time betting insights.
One standout tool, the Edge Finder, identifies betting opportunities by comparing a model's predicted probabilities with the implied probabilities from sportsbook odds. This method isn’t just theoretical - it’s proven. Within WagerProof's system, prioritizing models based on calibration rather than raw accuracy can lead to a return on investment (ROI) of +34.69%, compared to a -35.17% ROI when accuracy alone is the focus.
Another key feature is the AI Game Simulator, which dives deep into current conditions, player performance, and historical matchups to simulate multiple scenarios. The result? A detailed and nuanced understanding of potential outcomes.
Additionally, WagerBot Chat acts as a real-time AI assistant, offering data-backed insights based on statistical models and live updates. Whether it’s injury reports or market shifts, WagerProof integrates live data seamlessly, providing recommendations that are both clear and well-supported by evidence.
Conclusion
The models discussed above lay the groundwork for a solid framework in predictive sports betting. The five classification models - Logistic Regression, Decision Trees and Random Forests, Support Vector Machines (SVMs), Neural Networks, and Gradient Boosting Machines (e.g., XGBoost) - each bring unique strengths to the table. Random Forests and XGBoost are known for their higher predictive accuracy, Neural Networks excel at identifying complex, non-linear patterns, and SVMs shine when working with high-dimensional data.
Success in sports betting doesn’t come from relying on just one model. Instead, it’s about adopting a balanced, multi-model strategy. Effective models prioritize probability accuracy over simply predicting winners, a critical distinction that can make or break profitability. This approach ensures better decision-making, especially when real money is at stake.
Enter WagerProof, a platform designed to turn these model strengths into actionable betting insights. By combining multiple classification techniques into a single, user-friendly interface, WagerProof simplifies the process. Tools like the Edge Finder, AI Game Simulator, and WagerBot Chat analyze thousands of data points in real time, identifying value bets where sportsbook odds and model predictions differ. Instead of spending hours on manual calculations, you get clear, data-driven insights that explain why a bet is worth placing.
Whether you’re new to sports betting or have years of experience, WagerProof offers a Free Plan to help you get started without any risk. Explore tools like the Edge Finder demo and basic stats, and when you're ready, upgrade to Premium for full access to AI-driven analysis, historical data, and a private Discord community.
FAQs
How does combining different classification models improve sports match predictions?
Combining multiple classification models using techniques like stacking or bagging can boost the accuracy and dependability of sports match predictions. By pooling predictions from various models, this method reduces errors linked to individual model biases and takes advantage of their unique strengths.
For instance, one model might be particularly good at spotting patterns in historical data, while another focuses on real-time variables. Together, they create a more thorough analysis. This approach not only reduces variability but also improves the overall consistency of forecasts, leading to smarter, data-informed decisions when predicting outcomes.
Why is it better to focus on calibration rather than accuracy in sports betting models?
In sports betting, calibration plays a crucial role in ensuring that a model’s predicted probabilities match up with actual outcomes. This alignment helps bettors make better-informed decisions and spot opportunities where the odds might offer value. Without proper calibration, even a highly accurate model can lead to poor betting choices. Why? Because accuracy alone doesn’t guarantee that the probabilities are represented correctly - an essential factor for profitable predictions.
Prioritizing calibration allows you to evaluate the true likelihood of events more effectively. This not only helps you identify discrepancies in the market but also sets you up to make smarter bets. Over time, this approach can significantly boost your chances of achieving consistent success in sports betting.
Why are neural networks effective for predicting sports outcomes?
Neural networks excel at predicting sports outcomes because they can sift through intricate patterns and relationships in extensive datasets. By analyzing factors like team performance, player statistics, and historical trends, they reveal insights that simpler models might overlook.
Take feedforward neural networks, for instance. Research has demonstrated their strong ability to predict NFL game results. Their capability to process and learn from data makes them a valuable resource for crafting precise sports predictions.
Related Blog Posts
Ready to bet smarter?
WagerProof uses real data and advanced analytics to help you make informed betting decisions. Get access to professional-grade predictions for NFL, College Football, and more.
Get Started Free