
Cross-Validation vs. Backtesting in Betting Models
Want your betting model to actually work? The secret lies in how you test it. Cross-validation and backtesting are two key methods to evaluate sports betting models, but they serve different purposes:
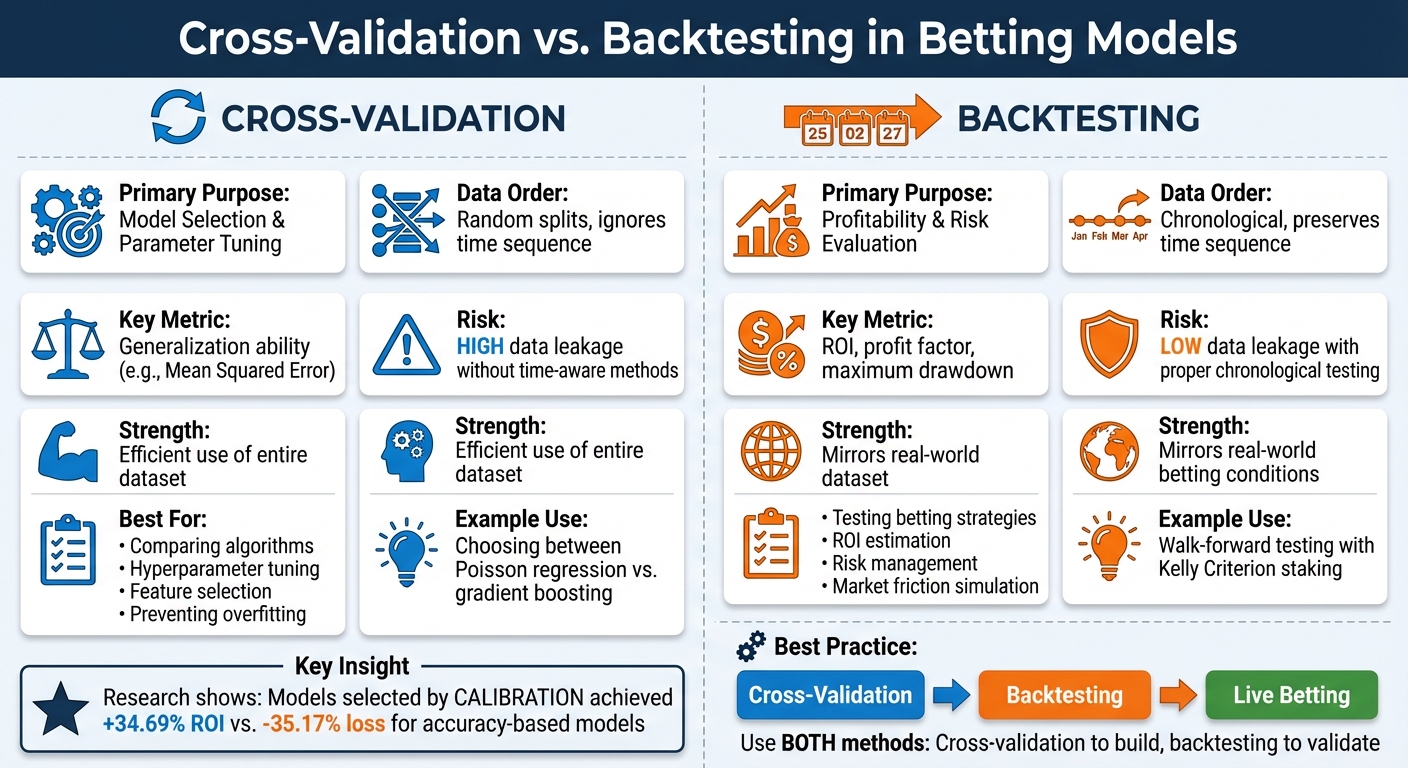
- Cross-validation: Splits your data into subsets to assess how well your model generalizes. It’s great for spotting overfitting and tuning parameters.
- Backtesting: Simulates how your model would perform in real betting scenarios by testing predictions on unseen, sequential data. It focuses on ROI, risk, and realistic outcomes.
Both methods are essential. Cross-validation helps refine your model, while backtesting ensures it’s ready for action. Together, they prevent costly mistakes like overfitting or data leakage, ensuring your betting strategy stands up to real-world challenges.
| Feature | Cross-Validation | Backtesting |
|---|---|---|
| Data Order | Random splits, ignores time | Chronological, respects time sequence |
| Goal | Model selection and tuning | Profitability and risk evaluation |
| Risk of Data Leakage | High without time-aware methods | Low with proper chronological testing |
| Best Use Case | Fine-tuning algorithms and parameters | Testing betting strategies and ROI |
Want a winning strategy? Use both methods: cross-validation to build a solid model and backtesting to confirm it works in practice.
Cross-Validation vs Backtesting in Sports Betting Models: Key Differences
Sport Betting Model Back Testing
What is Cross-Validation?
Cross-validation helps ensure your betting model identifies real patterns instead of merely memorizing noise. Instead of relying on a single model, this technique splits your historical data into multiple subsets - known as folds - and trains the model several times, each time using a different portion of the data for testing. This approach provides a better estimate of how the model will perform on unseen games.
Think of it like preparing for an exam. If you only study the exact questions that will appear, you might ace the test - but it doesn’t mean you’ve truly understood the material. Cross-validation works similarly, requiring your model to demonstrate it has learned the underlying patterns, not just the quirks of past data.
The most popular method, 10-fold cross-validation, divides the data into ten equal parts. The model trains on nine parts and tests on the tenth, repeating this process ten times so that each fold is used for testing exactly once. The final results are averaged, giving a more reliable estimate of performance.
How Cross-Validation Works
Here’s a simplified breakdown of how k-fold cross-validation operates:
- The dataset is divided into k equal-sized, non-overlapping subsets . For instance, with 5-fold cross-validation on a dataset of 1,000 NBA games, each fold would contain 200 games.
- The model trains for k iterations. In each iteration, one fold is held out as the test set, while the remaining k-1 folds are used for training.
- A performance metric (like Mean Squared Error) is calculated on the validation fold.
- The performance metrics from all k iterations are averaged to estimate the model’s generalization ability .
"The goal of cross-validation is to estimate the test error associated with a statistical model or select the appropriate level of flexibility for a particular statistical method." - QuantStart
A key consideration for sports betting is that standard random-split cross-validation isn’t suitable for time-series data, such as game results. Randomly shuffling games from different seasons can lead to data leakage, where the model inadvertently trains on future data to predict past outcomes. To address this, specialized methods like walk-forward validation (which uses an expanding window) or purged cross-validation are used. These techniques maintain the correct chronological order by introducing time gaps between the training and testing sets .
Benefits of Cross-Validation in Betting Models
Cross-validation is particularly useful for spotting overfitting - when a model seems highly accurate but is actually capturing random fluctuations, such as a brief injury streak or an unusual home-court advantage, that won’t repeat . By evaluating performance across multiple data splits, cross-validation helps confirm whether the model’s predictive edge is based on real patterns or just historical noise.
It also sheds light on model stability by producing a range of performance metrics rather than a single, potentially misleading result. For example, in a test using FTSE100 data, 10-fold cross-validation reduced the average test error to 0.8, compared to a much higher and less consistent error of 1.9 when using a simple 50/50 random split.
For sports bettors, consistent performance across all folds translates to greater confidence in the model’s predictions before any money is put at risk. This thorough evaluation lays the groundwork for understanding how backtesting can provide a complementary perspective.
What is Backtesting?
Backtesting is a method that simulates how a betting model would have performed in the past, offering a glimpse into its potential profitability. Unlike cross-validation, which evaluates a model's ability to generalize across data splits, backtesting focuses on replicating the sequential, real-world betting environment. It not only checks if your model picks winners but also measures the financial outcomes - how much profit or loss you might have experienced using real money and the actual odds available at the time.
The goal is to create a realistic simulation of live market conditions. For instance, if you're testing a model on the 2023 NBA season, it’s crucial to avoid training it with data from games that occurred after the ones you're predicting. Using future data would create an unrealistic advantage that simply doesn’t exist in real-world betting.
"The idea of backtesting is to replicate a realistic scenario. The training data should correspond to the data available for training a model at the moment of making a prediction." - Eryk Lewinson, Data Scientist
In essence, backtesting answers the critical question: Would this model have made money? It evaluates metrics like Return on Investment (ROI), profit factor, and maximum drawdowns - key figures that matter when you're putting your bankroll on the line.
How Backtesting Works
The most common approach to backtesting is walk-forward validation, which maintains the chronological order of games. This method uses either an expanding window (where the training set grows as time progresses) or a rolling window (which focuses on a fixed period, such as the last two seasons).
Here’s how it works: train the model on past data up to a specific date, then test it on the games that immediately follow. Repeat this forward-moving process to mimic live betting conditions. To ensure accuracy, introduce a purging step - a time gap between training and testing - to prevent highly correlated data from influencing results. For example, if a star player is injured in Game 50, that information shouldn’t affect predictions for Game 48.
Backtesting also incorporates real-world challenges like market friction. This includes accounting for factors such as commissions (the "vig"), liquidity limits, and slippage, where odds shift before you can place a bet. Ignoring these elements can lead to overly optimistic results that don’t reflect actual betting outcomes.
This systematic process not only mirrors real-world betting but also lays the groundwork for understanding its practical benefits.
Benefits of Backtesting in Betting Models
Backtesting is invaluable for determining whether your model's edge translates into actual profit. A study published in Machine Learning with Applications in June 2024 highlighted this using NBA data. Researchers trained machine learning models across multiple seasons and tested their betting performance on a single season using published odds. The results were striking: models selected based on calibration (how well predicted probabilities aligned with actual outcomes) achieved an ROI of +34.69%, while models chosen for their accuracy resulted in a loss of -35.17%. In the best-case scenario, calibration-based models reached +36.93% ROI, compared to just +5.56% for accuracy-based models.
"Sports bettors who wish to increase profits should therefore select their predictive model based on calibration, rather than accuracy." - Machine Learning with Applications
Beyond profitability, backtesting reveals weaknesses in risk management. It shows the maximum drawdown - your largest peak-to-valley bankroll drop - helping you gauge how much capital you need to endure losing streaks. It also highlights whether your model is overfitted, meaning it has memorized historical quirks (like a temporary injury trend) instead of identifying patterns likely to persist in the future.
Moreover, backtesting evaluates your model's stability across different market conditions, such as rule changes, team dynamics, or shifts in how bookmakers set odds. By testing your strategy on multiple seasons or leagues, you can ensure that your edge isn’t just a lucky result from one specific year. This rigorous process builds confidence that your model is ready for live markets where real money is on the line.
"Backtesting is an important first step for anyone who wants to create a strong and reliable sports betting strategy. By testing a strategy on past matches, you can check how much profit it might make and how risky it is before using real money." - Great Bets
Key Differences Between Cross-Validation and Backtesting
Both cross-validation and backtesting evaluate betting models, but they handle time in fundamentally different ways. In the context of sequential betting data, this distinction is crucial for understanding their respective strengths and limitations.
Cross-validation involves shuffling data, which can lead to the model training on future information, introducing what's known as look-ahead bias. This creates data leakage, allowing models to pick up on patterns from data that wouldn’t have been available at the time of prediction. Techniques like k-fold cross-validation assume that data points are independent and randomly distributed, but this assumption doesn’t hold in sports betting, where events occur in a strict sequence and information flows only forward.
Backtesting, particularly when using walk-forward validation, maintains the chronological order of events. Training data always precedes testing data, ensuring that the process mimics real-world betting scenarios. This approach provides a realistic evaluation of a strategy’s performance, including metrics like return on investment (ROI).
The objectives of these methods also diverge. Cross-validation focuses on selecting the best model, whether it’s comparing a Poisson model to a machine learning algorithm or fine-tuning hyperparameters.
"Cross-validation is asymptotically uninformative about the expected test error of any given predictive rule, but allows for asymptotically consistent model selection." - Stefan Wager, Stanford University
Backtesting, on the other hand, aims to answer a practical question: Would this strategy have turned a profit?
For strategies that rely on precise probability estimates, such as those employing the Kelly Criterion, proper calibration is essential. Studies have shown that selecting models based on calibration can lead to significantly higher ROI compared to choosing models based solely on accuracy.
Comparison Table: Cross-Validation vs. Backtesting
| Feature | Cross-Validation | Backtesting (Walk-Forward) |
|---|---|---|
| Data Order | Randomly shuffled; ignores time | Chronological; preserves time sequence |
| Primary Goal | Model selection and hyperparameter tuning | Strategy validation and ROI estimation |
| Risk of Data Leakage | High - future data can inadvertently train past predictions | Low - training data always comes before testing |
| Data Usage | Uses all data points for both training and testing | Limited by the chronological frontier |
| Best Use Case | Tuning parameters in Poisson models for scoring rates | Testing strategies like the Kelly Criterion using historical odds |
| Major Strength | Efficient use of the entire dataset | Mirrors real-world deployment conditions |
| Major Weakness | Susceptible to look-ahead bias | Can be computationally intensive with frequent refitting |
Understanding these differences helps clarify when each method is most appropriate for evaluating betting models.
When to Use Cross-Validation in Betting Models
Cross-validation is a key step in fine-tuning and selecting the best algorithm for your betting model. Unlike backtesting, which evaluates whether your strategy would have been profitable in the past, cross-validation focuses on optimizing your model before you put it into action. It helps you decide on the most effective algorithm and fine-tune parameters to avoid overfitting.
Take hyperparameter tuning as an example. If you're building a neural network to predict NBA game outcomes, you might need to figure out the ideal number of layers for your network or the maximum depth for a random forest. Cross-validation evaluates performance across multiple data splits, ensuring your model doesn’t become too tailored to a specific set of historical data.
Another use case is determining which features improve your predictions. Say you're considering adding variables like player efficiency ratings or home-court advantage. Cross-validation allows you to test different feature combinations, helping you decide which ones add real value. This approach not only sharpens model parameters but also enhances your understanding of which features truly matter.
For bettors who rely on the Kelly Criterion, calibration often takes precedence over raw accuracy. As seen in the NBA study mentioned earlier, selecting models based on calibration through cross-validation led to far better returns on investment (ROI) compared to choosing models based solely on accuracy.
Practical Applications of Cross-Validation
Cross-validation is particularly helpful when comparing different modeling techniques. For instance, if you're deciding between a Poisson regression and a gradient boosting model for predicting game outcomes, cross-validation can guide you. As Stefan Wager from Stanford University explains:
"Cross-validation is asymptotically uninformative about the expected test error of any given predictive rule, but allows for asymptotically consistent model selection."
In other words, while it may not perfectly predict your model's final performance, it reliably identifies which approach is likely to work better.
When working with limited data, cross-validation becomes even more valuable by rotating training and validation sets to maximize insights. For time-series data, like sports outcomes, purged k-fold cross-validation is recommended. This method excludes training data that is too close in time to your validation set, avoiding the risk of "leaking" future information into your training process.
Platforms like WagerProof use these rigorous validation techniques to ensure their models are well-calibrated and based on genuinely predictive features. This results in more dependable data for identifying value bets and spotting anomalies in real-time betting markets.
When to Use Backtesting in Betting Models
After refining your model through cross-validation, backtesting becomes the next step to confirm its profitability in real-world scenarios. While cross-validation helps you choose the best algorithm and fine-tune its parameters, backtesting determines if your strategy can actually generate profit when applied to real betting conditions. Think of it as the final checkpoint before risking actual money.
The main goal of backtesting is to evaluate both profitability and risk. This means analyzing metrics like return on investment (ROI), maximum drawdown, and how your bankroll might handle losing streaks. As Great Bets puts it:
"Backtesting is an important first step for anyone who wants to create a strong and reliable sports betting strategy. By testing a strategy on past matches, you can check how much profit it might make and how risky it is before using real money".
Backtesting also incorporates real-world factors that cross-validation often overlooks - things like bookmaker commissions (the "vig"), odds availability, slippage, and the difference between opening and closing lines. For instance, a model showing a 5% theoretical edge can easily turn unprofitable when you account for a 4.5% commission and limited liquidity on certain bets.
It’s also an opportunity to test staking strategies, comparing approaches like flat betting to more dynamic methods like the Kelly Criterion. Research shows that Kelly betting is only effective when your model is well-calibrated - meaning a predicted 60% probability actually results in a win 60% of the time.
Beyond profitability, backtesting is crucial for verifying model calibration. This is especially important when using strategies like the Kelly Criterion, where the accuracy of probability estimates directly impacts staking success. Let’s explore how these ideas play out in real-life backtesting scenarios.
Examples of Backtesting in Practice
One of the most reliable methods for backtesting sports betting models is walk-forward testing. This approach maintains the correct temporal order by training on one time period and testing on the next. For example, you might train an NFL model on the 2022 and 2023 seasons, then test it on the 2024 season using only the odds available at kickoff. This avoids look-ahead bias, which could occur if you used closing lines that weren’t available at the time of betting .
When running backtests, it’s essential to include execution costs in your simulations. This means accounting for bookmaker margins and realistic odds to avoid overly optimistic projections. If your strategy shows an unusually smooth equity curve or extremely high profit factors, it could be a sign of overfitting - since real betting environments rarely produce flawless results.
For strategies like the Kelly Criterion, backtesting is even more critical. A 2024 study published in Machine Learning with Applications highlighted the importance of calibration. The study found that well-calibrated models achieved a +36.93% ROI, while accuracy-focused models only managed +5.56%. As the researchers noted:
"Kelly betting only works with a well-calibrated model".
Without proper backtesting, aggressive staking strategies like Kelly can quickly drain your bankroll if the model’s probabilities are off.
Platforms such as WagerProof take these principles seriously, applying rigorous backtesting methods to their statistical models. They ensure their predictions account for real-world market conditions, and their probability estimates are fine-tuned to identify genuine value bets.
Combining Cross-Validation and Backtesting for Better Results
Bringing cross-validation and backtesting together helps tackle the weaknesses of evaluating betting models in isolation. This combination ensures models are both fine-tuned and tested under realistic conditions. Use cross-validation to refine model parameters and backtesting to simulate real-world performance. Together, they create a balanced workflow that capitalizes on the strengths of each method while minimizing their limitations.
Cross-validation is particularly effective for comparing models and identifying optimal parameters. It maximizes the use of available data and reduces statistical errors during model evaluation. On the other hand, backtesting reflects actual betting conditions by accounting for factors like bookmaker commissions, odds fluctuations, and betting limits.
To avoid overfitting, divide historical data into three parts: training, validation, and a held-out test set. This approach ensures your model doesn’t get overly tailored to backtest quirks, which can lead to strategies that seem promising in theory but fail in practice.
This integrated strategy creates a smooth evaluation process, connecting model refinement with real-world simulation.
Hybrid Workflow for Betting Models
Start with purged cross-validation on your training and validation data. Unlike standard k-fold cross-validation, which ignores the chronological order of events, purged cross-validation respects time order. For example, it avoids training on games from December and testing on games from October, which could lead to misleading performance estimates. By introducing a deliberate gap between training and validation sets, purged cross-validation prevents information leakage from closely related events.
During this stage, prioritize calibration metrics over simple accuracy. A 2024 study on NBA betting models highlighted the importance of calibration - how well predicted probabilities align with actual outcomes. Models chosen based on calibration achieved an average ROI of +34.69%, while those selected for accuracy resulted in a -35.17% loss. The study emphasized:
"Sports bettors who wish to increase profits should therefore select their predictive model based on calibration, rather than accuracy." – Conor Walsh and Alok Joshi
Once you’ve chosen the best model through cross-validation, shift to walk-forward backtesting with your held-out test data. This method involves training on one time period and testing on the next - for example, training on the 2022–2023 seasons and testing on 2024. Walk-forward backtesting helps uncover issues that cross-validation might miss, such as shifts in league dynamics or team strategies.
Your backtesting process should include all realistic market constraints: bookmaker vig, stake limits, slippage due to odds changes, and sportsbook liquidity. Be cautious of overly smooth profit curves or unusually high returns in your backtest results - these are often signs of overfitting rather than a genuinely robust strategy.
Platforms like WagerProof demonstrate the effectiveness of this hybrid approach. They use cross-validation to refine algorithms and rigorous backtesting to evaluate performance under real market conditions. Their transparent interface not only provides predictions but also reveals the underlying data and methodology, ensuring models are well-calibrated and account for practical betting challenges. By combining these techniques, WagerProof helps identify genuine value bets, reducing the risk of chasing signals that fail when real money is involved. This workflow strengthens your strategy, blending precise tuning with actionable market insights.
Conclusion
Cross-validation and backtesting work hand in hand - one evaluates how well a model generalizes, while the other tests its performance in simulated real-world conditions. Relying solely on one method can leave gaps in your strategy that might go unnoticed.
Research from February 2024 found that models refined through calibration deliver much higher ROI compared to those chosen purely based on accuracy. This highlights the importance of combining both techniques for a more reliable evaluation.
A hybrid workflow - starting with purged cross-validation for selecting models, followed by walk-forward backtesting to validate performance - creates a solid foundation. This approach reduces overfitting and accounts for the ever-changing dynamics of sports data. It ensures your model is identifying meaningful patterns rather than clinging to quirks in historical data.
WagerProof employs this dual-method approach to produce accurate, well-calibrated predictions supported by transparent data. By combining these techniques, WagerProof can identify true value bets while filtering out strategies that only seem profitable on paper. This balanced evaluation is key to turning historical trends into consistent, profitable betting outcomes.
FAQs
How do I avoid data leakage when validating a betting model?
To safeguard against data leakage, it's crucial to use proper validation methods. One effective approach is purged cross-validation, which eliminates look-ahead bias, particularly in time series datasets. Additionally, ensure a clear separation between training and testing data - mixing them can distort results. Avoid the temptation to re-fit your model on combined datasets after validation, as this undermines the integrity of your evaluation.
For more precise performance estimates, nested cross-validation is a helpful technique. It mirrors real-world scenarios by providing a more realistic view of how the model will perform on unseen data. Lastly, always maintain the temporal sequence of your data. Letting future data influence the training process can lead to misleading outcomes.
What should I measure in a backtest besides ROI?
When analyzing performance, don’t just focus on ROI. Metrics like the Sharpe ratio (which measures return per unit of risk), drawdowns, and consistency of returns over time provide a clearer picture of the model’s effectiveness. It’s also crucial to check for overfitting by evaluating how stable the model is across various data samples and time periods. These steps ensure the model isn’t just profitable but also dependable and capable of delivering accurate predictions in different scenarios.
Why does calibration matter more than accuracy for betting?
When it comes to betting, calibration often outweighs accuracy in importance. Why? Because calibration ensures that the probabilities you predict align closely with actual outcomes. This alignment is crucial for making smarter decisions about how much to bet and managing risk effectively.
While accuracy focuses on how often predictions are correct, calibration digs deeper. It evaluates whether your predicted probabilities truly reflect real-world frequencies. For example, if you predict a 70% chance of an event happening, proper calibration means that event should occur 70% of the time over the long run. Without this, bettors risk falling into traps like mispricing or overconfidence.
In the long term, well-calibrated models provide more dependable betting edges and help maintain profitability. On the other hand, models that chase accuracy alone can generate probabilities that mislead, ultimately undermining your betting strategy. Calibration keeps your predictions grounded and reliable, which is essential for sustained success.
Related Blog Posts
Ready to bet smarter?
WagerProof uses real data and advanced analytics to help you make informed betting decisions. Get access to professional-grade predictions for NFL, College Football, and more.
Get Started Free