
Real-Time Anomaly Detection: Challenges and Fixes
Real-time anomaly detection in sports betting is about identifying unusual patterns - like shifts in odds or spikes in betting volume - as they happen. This ensures faster responses to potential risks such as fraud or market imbalances. The process involves spotting three types of anomalies: point anomalies (single unusual events), collective anomalies (trends across multiple data points), and contextual anomalies (situational irregularities).
Key Takeaways:
- Benefits: Detects value betting opportunities, combats fraud (e.g., match-fixing), and protects market integrity during live events.
- Challenges:
- High-speed data streams: Systems must process massive data in milliseconds.
- False positives: Sports unpredictability makes it hard to differentiate legitimate changes from anomalies.
- Data integration issues: Combining data from multiple sources quickly and accurately is complex.
- Solutions:
- Use advanced models like LSTM and RNN autoencoders for precise anomaly detection.
- Employ tools like Apache Flink for real-time data processing.
- Combine machine learning with rule-based triggers for reliable validation.
These strategies help sports betting platforms handle data efficiently, reduce false alarms, and maintain trust in live betting environments.
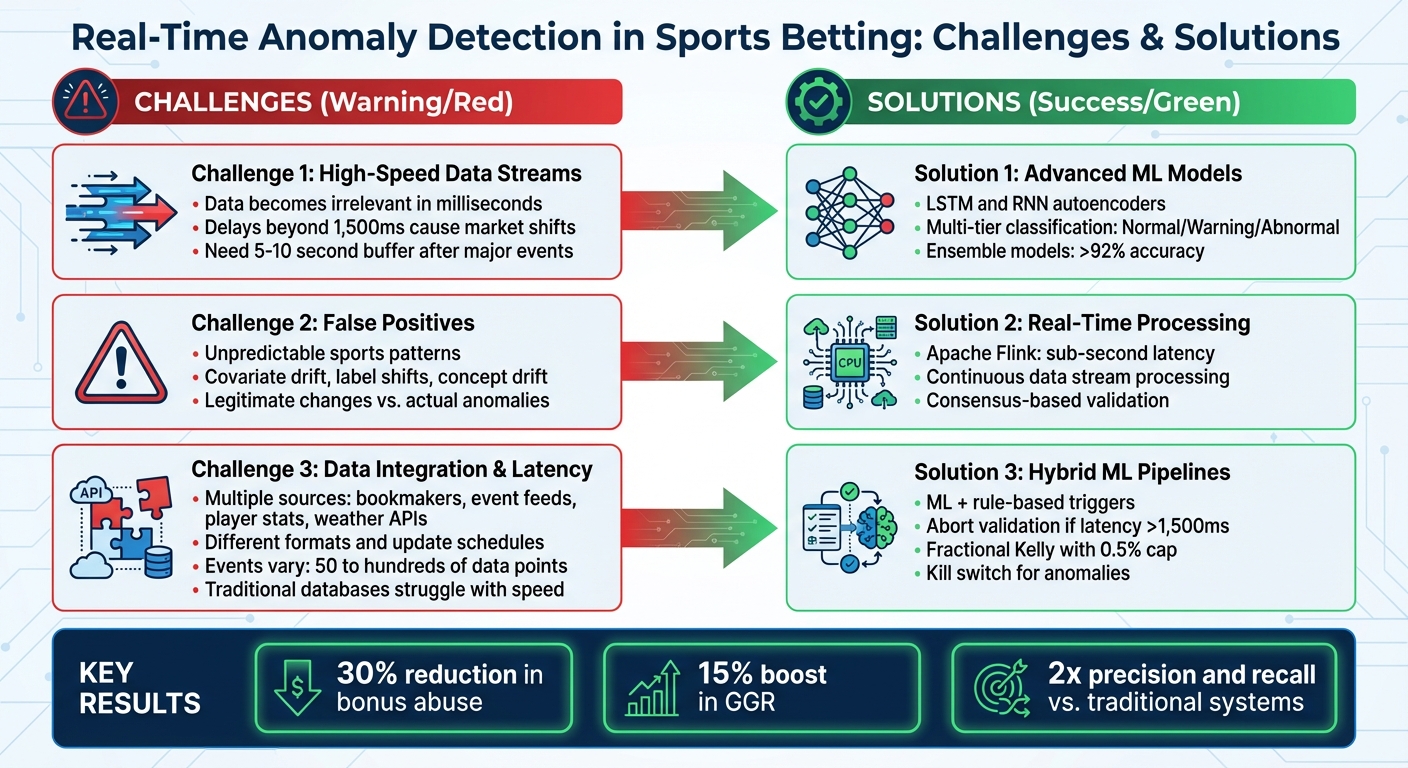
Real-Time Anomaly Detection Challenges vs Solutions in Sports Betting
Mastering real-time anomaly detection with open source tools by Olena Kutsenko
Main Challenges in Real-Time Anomaly Detection
Real-time anomaly detection in sports betting comes with its own set of hurdles. The sheer volume of data and the unpredictable nature of sports events make it tough for even advanced detection systems to keep up.
High-Speed Data Streams
Sports betting platforms handle an overwhelming amount of data every second - live odds updates, play-by-play stats, and player tracking details flood these systems constantly. The challenge isn’t just the volume; it’s the speed. Data becomes irrelevant in milliseconds, and during volatile events, delays beyond 1,500 ms can cause significant market shifts. To avoid errors, systems often need a 5–10 second buffer after major events to let the market settle before running anomaly checks.
But speed isn’t the only issue. The unpredictable nature of sports adds another layer of complexity.
False Positives from Unpredictable Sports Patterns
Sports outcomes are influenced by countless factors - athlete performance, weather, referee calls, and sheer luck. A sudden shift in odds might not always signal foul play; it could be a legitimate reaction based on data-driven betting strategies, like a minor injury to a key player. This unpredictability leads to challenges like covariate drift, label shifts, and concept drift, all of which can trigger false alarms.
As Newdata.Cloud emphasizes:
In continuous learning, never let speed outpace safety - each automated update must be auditable, reversible, and economically sensible.
The problem becomes even trickier when multiple data sources are involved.
Data Integration and Latency Problems
Real-time detection systems rely on data from various sources - bookmakers, event feeds, player stats, and even external inputs like weather APIs. Each source has its quirks: different formats, update schedules, and field names. To make this data usable, it must be quickly normalized, which isn’t easy. Some events might have 50 data points, while others have hundreds, creating inconsistencies that can confuse detection models.
On top of that, advanced models like LSTMs need significant processing power. Every extra millisecond spent on normalization or feature computation adds to latency, potentially invalidating the analysis. Traditional databases also struggle to query such massive datasets fast enough to keep up with live events. Tackling these integration and latency issues is critical for maintaining accurate real-time anomaly detection.
Solutions to Address Anomaly Detection Challenges
Machine learning and distributed processing offer practical ways to tackle challenges in real-time anomaly detection. Let’s explore how specific tools and strategies make this possible.
LSTM and RNN Autoencoders for Precise Detection
LSTM and RNN autoencoders excel at identifying anomalies in sequential betting data. These models learn what constitutes "normal" betting behavior and flag unusual patterns by analyzing the reconstruction error - the gap between expected and actual outcomes. Because they are tailored for sequential data, they can monitor how betting odds evolve over time and pick up on even subtle irregularities.
To reduce false positives, a multi-tier classification system is often used, categorizing data into "Normal", "Warning", or "Abnormal" levels. This approach ensures greater accuracy and reliability.
Performance metrics highlight the effectiveness of ensemble models, which combine multiple algorithms to achieve over 92% accuracy in detecting betting anomalies. Here’s a breakdown of key models:
| Model Type | Accuracy | Key Characteristics |
|---|---|---|
| Ensemble Model | >92% | Aggregates outputs from multiple models to lower false positives |
| Random Forest (RF) | >92% | Employs decision trees and bagging for robust results |
| K-Nearest Neighbor (KNN) | >92% | Works well with smaller datasets using distance metrics |
| Logistic Regression (LR) | ~80% | Predicts binary outcomes using supervised learning |
| Support Vector Machine (SVM) | ~80% | Creates decision boundaries; may require RBF kernels for non-linear scenarios |
To ensure flagged anomalies are genuine and not just statistical outliers, domain experts play a vital role in validating findings.
Apache Flink for Real-Time Data Processing

Real-time processing is a cornerstone of effective anomaly detection. Apache Flink stands out by managing unbounded data streams with sub-second latency, allowing for immediate recalculations of odds and fraud detection. Unlike traditional databases, Flink processes incoming data continuously, avoiding delays and bottlenecks.
When paired with anomaly detection models like Random Forest, KNN, and SVM, Flink coordinates their outputs to ensure accuracy. An "abnormal" label is only applied when all models agree, significantly reducing false positives while maintaining real-time functionality.
These capabilities form the backbone of a robust anomaly detection system, further enhanced by specialized AI agents.
WagerProof AI Agents for Automated Detection
WagerProof AI agents bring an additional layer of precision to anomaly detection. These agents continuously monitor sports data, evaluating matchups and identifying outliers when prediction market spreads deviate unexpectedly.
The platform uses a consensus-based system to classify patterns into "normal", "warning", or "abnormal" categories. This ensures that anomalies with high confidence levels are flagged promptly, while false alarms are kept to a minimum. Additionally, WagerBot Chat integrates live data - such as weather updates, injury reports, and model predictions - providing users with clear and actionable insights. Importantly, this transparency ensures there are no hidden algorithms or manipulated results.
Implementing Hybrid ML Pipelines for Anomaly Validation
To reliably validate anomalies during sudden changes in gameplay, combining machine learning (ML) outputs with rule-based triggers offers a more dependable approach. This hybrid method strengthens detection systems by reducing false alarms and enhancing overall reliability.
ML outputs should be treated as preliminary estimates and fine-tuned with real-time triggers. For example, in-game events like red cards, player injuries, or weather delays can activate regime flags that override outdated ML predictions. A notable example of this approach is AB Tasty’s 2021 monitoring of 4,000 client time series. They paired a Holt-Winters ML model with a "median rule" that compared current values to the median of the previous five weeks. This strategy effectively filtered out false trends caused by temporary events, leading to more accurate anomaly detection.
To address latency issues, anti-latency measures should be in place. For instance, anomaly validation should be aborted if feed latency surpasses 1,500ms following volatile events. This can be achieved by logging the timestamps of data arrival and dispatch, with a 5–10 second discard window after major events to allow markets to stabilize before resuming detection.
Transient errors can be minimized by ignoring anomalies lasting less than two hours and by setting minimum traffic thresholds. This helps avoid false alarms caused by minor, statistically insignificant changes in low-volume data. When it comes to staking, applying Fractional Kelly with a hard cap of 0.5% per ticket limits exposure. Additionally, a kill switch should be implemented to halt operations if session drawdowns exceed five times the median session loss or if calibration error doubles the target threshold.
Conclusion
Real-time anomaly detection in sports betting comes with its fair share of hurdles. High-speed data streams, unpredictable game patterns causing false positives, latency issues, and ever-evolving fraud tactics make this a tough landscape to navigate. Traditional systems often fall short, leaving gaps that can lead to problems like bonus abuse, match-fixing, and account takeovers. These challenges demand new approaches that can keep up with the pace and complexity of the industry.
Advanced AI and real-time processing are stepping up to fill these gaps. For example, hybrid AI pipelines have shown impressive results, cutting bonus abuse by 30% and boosting Gross Gaming Revenue (GGR) by 15%. Similarly, RNN-based methods have delivered double the precision and recall rates compared to older systems.
Platforms like WagerProof are leading the charge with cutting-edge tools. Their 24/7 market monitoring provides immediate, AI-driven insights to spot anomalies as they happen. The Edge Finder tool, for instance, uses over 50 statistical models to compare live odds, uncovering value bets and market inefficiencies. Meanwhile, WagerBot Chat goes beyond surface-level analysis by integrating factors like weather, odds, injury reports, and model predictions into actionable advice - offering clarity without relying on opaque algorithms.
FAQs
What’s the best way to set anomaly thresholds without too many false alarms?
To reduce false alarms, it’s essential to tweak settings like confidence levels, detection sensitivity, and window sizes. For example, adjusting confidence intervals - whether 80%, 95%, or 99% - helps strike a balance between catching anomalies and minimizing false positives. Regularly calibrating predicted anomaly scores against actual false positive rates and validating the system’s performance ensures consistent reliability. Additionally, using sufficient historical data in threshold calculations prevents overreacting to minor fluctuations while still maintaining accurate detection.
How do you handle data feed delays without missing real anomalies?
Managing data feed delays while detecting anomalies requires a thoughtful approach to ensure accuracy without sacrificing timeliness. One effective strategy is configuring query delays to account for late-arriving data, allowing the system to process information more thoroughly. Additionally, keeping an eye on ingestion latency can help you make real-time adjustments to processing as needed.
Techniques like watermarking, windowing, and state management in streaming pipelines play a crucial role here. Watermarking helps differentiate between late data and missing data, while windowing organizes data into time-based segments for better handling. State management ensures the system can maintain context over time, even as new data arrives.
By combining these methods, you can strike the right balance between minimizing latency and ensuring data completeness. This reduces the risk of missing anomalies that might otherwise go undetected due to delayed data ingestion.
When should you use rules vs ML vs a hybrid approach?
In real-time anomaly detection, rules are ideal for straightforward, predefined scenarios - think of situations like breaches of specific thresholds. On the other hand, machine learning (ML) shines when it comes to spotting intricate, shifting patterns in dynamic settings, such as live sports betting. A hybrid approach brings the best of both worlds: rules tackle simple anomalies, while ML dives into more complex patterns. This combination boosts accuracy and flexibility, making it a reliable solution for high-stakes systems where precision matters most.
Related Blog Posts
Ready to bet smarter?
WagerProof uses real data and advanced analytics to help you make informed betting decisions. Get access to professional-grade predictions for NFL, College Football, and more.
Get Started Free