
Real-Time Model Validation with Event-Driven Pipelines
In sports betting, predictive models can become outdated quickly due to events like injuries or red cards. Traditional batch processing often fails to keep up with these rapid changes. Real-time model validation solves this by continuously monitoring and adjusting model performance using event-driven pipelines. Key technologies like Apache Kafka, Spark Streaming, and Apache Druid enable sub-second data processing, ensuring predictions remain aligned with live market conditions.
Key Takeaways:
- Real-Time Monitoring: Tracks metrics like Expected Calibration Error (ECE) and Live Execution Value (LEV) to detect and address model drift.
- Failsafes: Automated systems cancel bets if data latency exceeds 1,500 ms or error rates spike.
- Technologies Used: Apache Kafka handles data ingestion, Spark Streaming processes events, and Apache Druid enables instant querying.
- Practical Example: Systems like Hoop Oracle process live sports data to predict outcomes with minimal latency.
This approach ensures accuracy and minimizes risks in high-stakes, fast-moving betting environments.
Event-Driven Architecture Explained in 10 Minutes | Apache Kafka

Core Components of Event-Driven Pipelines
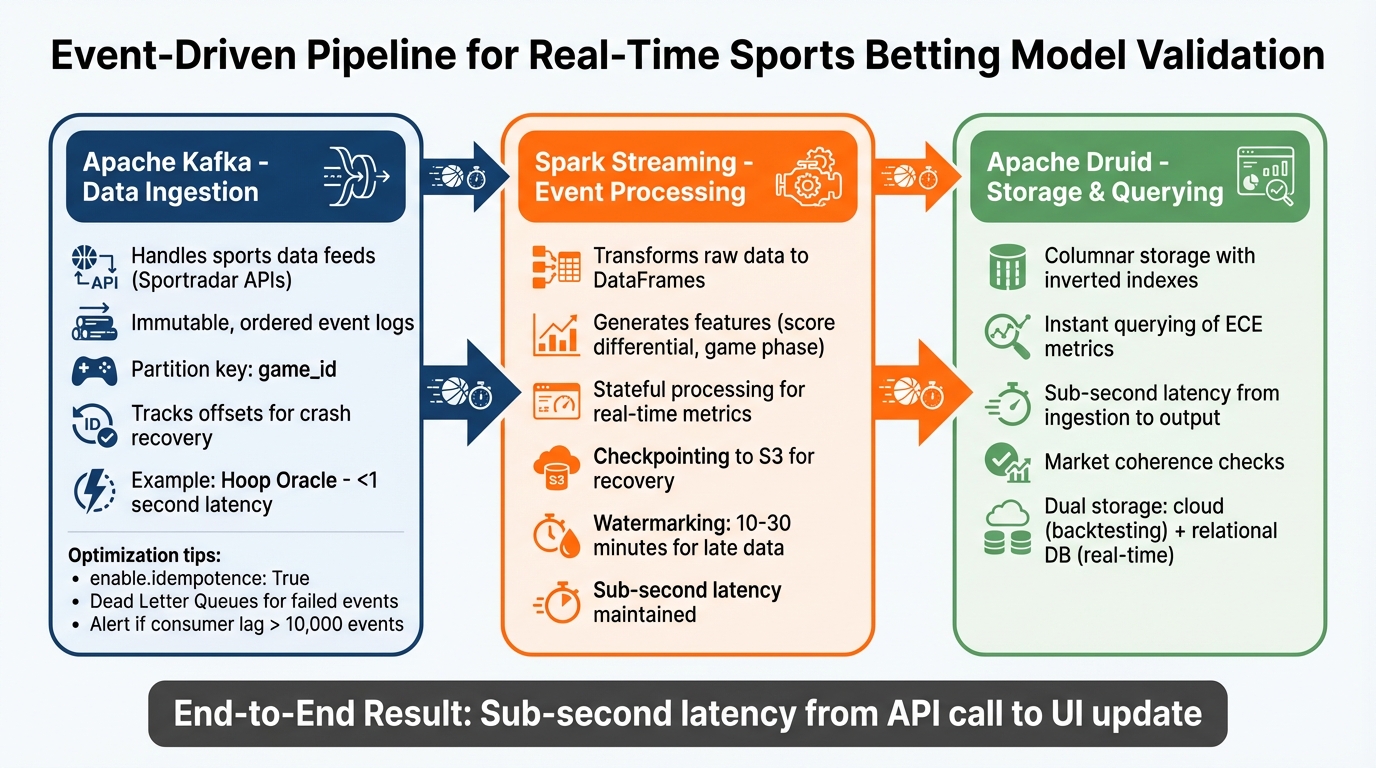
Real-Time Model Validation Pipeline Architecture for Sports Betting
Event-driven pipelines hinge on three key technologies, each playing a unique role: Apache Kafka handles data ingestion, Spark Streaming processes the incoming events, and Apache Druid (or a similar OLAP engine) stores and indexes the results for instant querying. Together, these components allow real-time model validation without waiting for batch updates.
Real-Time Data Ingestion with Apache Kafka
Apache Kafka serves as the distributed backbone that separates data sources from processing systems. For example, sports data feeds like Sportradar APIs - providing updates on scores, injuries, and odds - publish events to Kafka topics. These events are stored as immutable, ordered records in an append-only log, which also supports historical data replay for quick model backtesting.
In sports betting, ordering guarantees are essential. By using a partition key such as game_id, Kafka ensures all events for a specific game are sent to the same partition and processed in strict chronological order. Kafka also tracks offsets (position markers for each consumer group) to enable services to resume processing after crashes without losing data. This ensures validation metrics align with the actual sequence of events, supporting accurate performance tracking.
A notable example is Hoop Oracle, a cloud-based system developed in December 2025 by a team including Yan Naing Aung. It predicted NBA win probabilities by using Confluent Kafka to ingest Sportradar API data every two minutes. The system, partitioned by game ID, achieved an end-to-end latency of under one second from the API call to the UI update. Avro serialization and a Schema Registry ensured a smooth, ordered data flow for PyTorch model inference.
"Start with Schema Registry: It saves countless hours of debugging." - Surendra Tamang, Software Engineer
To optimize Kafka pipelines:
- Set
enable.idempotence: Truefor Kafka producers to avoid duplicate messages during network retries. - Use Dead Letter Queues (DLQ) to handle events that fail validation by routing them to a separate topic for manual review, avoiding disruptions to live streams.
- Monitor consumer lag - the gap between the latest message in Kafka and the last message processed - and set alerts if it exceeds 10,000 events.
Continuous Data Processing with Spark Streaming
Once Kafka ingests the data, Spark Streaming takes over to refine and enhance the events for real-time analysis. It transforms raw byte arrays into DataFrames, applies validation rules, and generates features like score differential or game phase (e.g., first quarter, overtime) before feeding the data into predictive models.
Spark's stateful processing allows it to maintain real-time metrics from continuous streams without reprocessing historical data. Key features like checkpointing save the pipeline's state to persistent storage (e.g., S3) for recovery in case of failure, while watermarking (usually set to 10–30 minutes) ensures late-arriving data, such as delayed score updates, is included in windowed aggregations. The Hoop Oracle system used these techniques to compute features and deliver live win probabilities with sub-second latency. This ensures that validation metrics always reflect the most up-to-date information, directly boosting model accuracy.
Analytics and Storage with Apache Druid
After processing, the data needs to be stored in a way that supports rapid querying of model performance metrics. Apache Druid and other OLAP engines excel at this, indexing processed events to allow dashboards to retrieve metrics like Expected Calibration Error (ECE) almost instantly, without scanning entire datasets.
Druid's columnar storage and inverted indexes enable fast, high-throughput writes and low-latency queries. Many production systems use a dual storage approach: cloud storage for offline backtesting and relational databases for real-time queries, achieving sub-second latency from ingestion to output.
The storage layer also supports market coherence checks. These ensure that related betting markets - like "Next Goal" and "Total Goals" - remain mathematically consistent after a model update. This prevents mismatches that could lead to arbitrage opportunities or user confusion.
With efficient storage and instant accessibility, these components work together to enable precise, real-time validation workflows.
Building Real-Time Validation Workflows
After setting up the pipeline components, the next step is creating a validation workflow that keeps a close eye on the model's performance. This system works to catch potential issues before they can affect betting decisions. A key part of this process is monitoring model drift - when predictions start to diverge from actual outcomes - and tracking critical performance metrics as they happen.
Using the Kafka, Spark, and Druid setup mentioned earlier, this workflow is designed to detect performance problems in real time. For example, by logging timestamps for data arrival, model updates, and bet dispatches, you can measure how old the data is at the time of decision-making. If the data age exceeds 1,500 ms during high-pressure moments - like right after a goal - an automated system can abort the action to avoid relying on outdated information.
Another important element is the use of feature layers that represent the current state of the game. These layers include state features (like the score and time left), momentum features (such as xG velocity), and regime flags (like red cards or timeouts). If any of these inputs fall outside expected ranges, validation alerts can highlight the issue before it impacts performance. Many systems also use Bayesian updating, which starts with a pre-match model and adjusts probabilities incrementally with every play-by-play event.
To add an extra layer of protection, automated failsafes are implemented. These act as guardrails, stopping execution immediately if session drawdowns or ECE thresholds surpass predefined limits. This approach ensures that minor issues don’t escalate into major losses. Additionally, detailed logs enable the system to detect drift and anomalies as they occur, keeping the workflow robust and responsive.
Model Drift Detection and Anomaly Identification
Detecting drift in live betting scenarios requires a different approach compared to traditional batch validation. Since in-play markets don’t have a definitive "closing line", pipelines instead track Live Execution Value (LEV). This metric compares the executed price to the mid-odds three seconds after a bet is placed. A persistent negative LEV% suggests the model is outperforming market adjustments, while a persistent positive LEV% indicates the model may be too slow or drifting.
Statistical tools like the Population Stability Index (PSI) and Kolmogorov-Smirnov (KS) tests are used to monitor shifts in feature distributions. A PSI score above 0.2 signals significant drift, requiring immediate attention.
In addition to LEV monitoring, statistical triggers provide another layer of oversight. For instance, drift can be flagged if overround sensitivity shifts over three consecutive match days or if the ECE during a live session exceeds twice the target value.
High-volume pipelines should also incorporate hash-based integrity logs. These logs create a continuous hash over event data, ensuring auditability and protecting against data tampering. This method leaves a verifiable record for every prediction and its corresponding outcome.
Performance Metrics and Real-Time Monitoring
Real-time dashboards bring all these metrics together, offering a clear view of the system's health. These dashboards pull data directly from the storage layer to provide instant visibility into any latency or validation issues. For example, latency metrics - like the time it takes from feed arrival to bet dispatch - are crucial for pinpointing bottlenecks.
| Metric | Purpose in Validation | Threshold/Target |
|---|---|---|
| LEV (Live Execution Value) | Detects live execution lag | Persistent positive LEV% signals lag |
| PSI (Population Stability Index) | Measures distribution shift | > 0.2 indicates significant drift |
| ECE (Expected Calibration Error) | Assesses probability calibration | Auto-halt if > 2× target |
These tools and metrics work together to ensure the system stays accurate, responsive, and reliable, even in fast-moving, high-stakes environments. By continuously monitoring for drift and anomalies, the workflow helps maintain peak performance while minimizing risks.
Optimizing Event-Driven Validation Pipelines for Sports Betting
To handle the fast-paced and high-volume nature of sports betting data, it's essential to refine the validation pipeline. The goal is to create systems that can scale efficiently while maintaining precision, even when processing a large volume of predictions across various sports and markets.
The main challenge? Striking the right balance between speed and accuracy. A pipeline that lags behind risks missing opportunities, while one that compromises on validation may produce unreliable outcomes. Below, we explore strategies for scalable data ingestion and ensemble model techniques to ensure both efficiency and reliability.
Scalable Ingestion for High-Volume Betting Data
Sports like basketball and football churn out hundreds of updates during a single game, each potentially triggering recalculations across multiple betting markets. To manage this, partitioned ingestion and market clustering can help distribute the workload across nodes, minimizing correlated risks. For example, linking the match winner market with related handicap lines - and restricting each cluster to one position per time slice - can prevent cascading issues when several interrelated bets shift simultaneously.
Another key strategy is incorporating post-event re-equilibration windows. After major events like a goal or a red card, markets often experience temporary volatility as odds adjust. By introducing a "discard window" of 5–10 seconds after such events, the system can avoid reacting to short-term noise, reducing the likelihood of poorly timed bets.
Different data types also demand tailored update frequencies. For instance:
- League schedules and rosters typically update daily.
- Real-time odds require sub-minute updates via WebSocket feeds to track rapid line shifts.
- Historical statistics often refresh daily, with a slight lag (3–4 days) to account for official corrections.
While these measures ensure efficient data flow, fine-tuning model accuracy requires robust ensemble validation techniques.
Ensemble Model Validation for Improved Accuracy
Ensemble models, which combine multiple algorithms, are highly effective for generating accurate predictions. However, validating these models in real time adds complexity, especially within a streaming workflow.
Three popular aggregation methods stand out:
- Weighted averaging prioritizes models with proven track records, though it requires thorough historical tracking.
- Z-score standardization adjusts for prediction variance but involves intricate statistical preprocessing.
- Median aggregation filters out extreme outliers, though it may miss sharp insights from niche models.
For live betting scenarios, incremental Bayesian updating ensures adaptability without needing full retraining. Starting with a pre-match model as a "prior", probabilities are updated dynamically as new events - like fouls, shots, or possession changes - occur. These methods complement earlier failsafe mechanisms, creating a robust framework for real-time validation.
How WagerProof Uses Event-Driven Pipelines for Automated Validation
WagerProof employs an event-driven architecture to validate predictions and deliver actionable insights as markets fluctuate. This system constantly tracks model performance across thousands of betting markets, quickly identifying discrepancies and opportunities. By doing so, users gain access to reliable, up-to-date data to inform their decisions. Here's how WagerProof integrates continuous monitoring and smart alerts to improve betting strategies.
WagerProof AI Research Agents for Continuous Model Monitoring
Using its event-driven pipeline framework, WagerProof deploys AI agents to monitor model performance in real time. These agents operate 24/7, analyzing over 50 adjustable parameters to detect when models deviate from expected outcomes. Each agent focuses on specific performance metrics aligned with its betting style and risk profile, triggering alerts when certain thresholds are crossed.
To maintain accuracy, the platform tracks four key drift indicators:
| Metric | Warning Sign for Model Drift | Recommended Action |
|---|---|---|
| ROI | Gradual weekly decline | Conduct immediate performance audit |
| ECE | Error exceeds 0.015 | Initiate model retraining |
| RPS (Ranked Probability Score) | Increasing score over a rolling window | Reassess feature importance |
| CLV | Consistently near zero | Lower stake sizes and check for variance |
When discrepancies arise between market spreads and internal models, an outlier alert is triggered. These alerts either highlight potential value bets or signal when to avoid betting on a game entirely. Users can trust these recommendations thanks to the platform's transparent tracking of each agent's performance history - no hidden data or manipulated win rates.
WagerBot Chat for Data-Driven Betting Recommendations
WagerBot Chat brings together live odds feeds, injury updates, weather conditions, and validated model predictions into a unified interface. It cross-references market odds with statistical models to deliver transparent, data-backed insights. Unlike generic chat interfaces prone to outdated or incorrect responses, WagerBot connects directly to professional-grade data sources, ensuring its recommendations reflect real-time market conditions.
When users inquire about specific matchups, WagerBot performs a multi-step analysis. It pulls live data from the event-driven pipeline, checks for recent line movements, and evaluates whether the current spread indicates genuine value or just noise. A validation layer ensures that every recommendation is based on verified data, not speculation. This approach gives users clear, actionable insights they can trust.
Conclusion
Event-driven pipelines are changing the game for how predictive models are validated in sports betting. By processing data in real time, these systems can flag potential issues before they affect decision-making. One standout feature is their ability to continuously monitor data freshness, triggering safeguards the moment data latency spikes. The real power here lies in the immediate feedback loop. Instead of waiting days or weeks to uncover model degradation, event-driven architectures identify anomalies in seconds. This is especially crucial during live betting, where market conditions can shift in the blink of an eye. For example, a 5–10 second discard window after major events allows markets to stabilize, reducing the impact of temporary distortions. This ensures that bettors receive timely and reliable recommendations.
WagerProof is a prime example of this approach in action. The platform uses event-driven architecture to deliver precise, data-backed insights through its AI agents and WagerBot Chat. It integrates diverse data feeds - like official league stats, historical records, and real-time odds - into a single, cohesive system. The Model Aggregator combines forecasts from more than 50 analytical methods to minimize individual model bias. Meanwhile, the Edge Finder leverages z-scores to pinpoint discrepancies between projections and market lines.
What sets WagerProof apart is its commitment to transparency. Every projection clearly displays the inputs, refresh rates, and live data sources used. WagerBot Chat goes a step further by explaining recommendations using verified professional data, steering clear of generic AI responses. Additional tools, like Public Money Splits, give users a deeper look into betting trends - highlighting the difference between casual bets and where professional bettors are putting their money.
FAQs
How do you validate a model when outcomes aren’t known yet in live betting?
Validating a model for live betting without knowing the outcomes requires real-time evaluation methods that adapt as new data flows in. This involves using event-driven pipelines to recalibrate predictions based on live odds, play-by-play statistics, and contextual factors like weather conditions or player injuries.
Techniques such as Bayesian updating help refine probabilities as fresh information becomes available, while methods like Platt Scaling adjust the model’s confidence levels to ensure accuracy. To measure performance effectively during live events, metrics like Closing Line Value (CLV) are used. CLV is particularly valuable for assessing how well the model’s predictions align with market movements, helping to manage risk in the fast-paced environment of live betting.
What happens if the data feed lags or arrives out of order?
If the data feed slows down or delivers information out of sequence, real-time validation steps in to spot anomalies, outliers, or inconsistencies. This process helps prevent flawed data from affecting models, ensuring predictions stay reliable and precise.
Which drift metric should I monitor first: LEV, ECE, or PSI?
PSI, or Prediction Strength Indicator, is a popular tool for detecting model drift and evaluating the stability of predictions over time. Its reliability makes it especially valuable for real-time model validation, particularly in industries like sports betting, where accuracy and consistency are critical. By monitoring PSI, you can identify shifts in model performance and ensure predictions remain dependable as conditions evolve.
Related Blog Posts
Ready to bet smarter?
WagerProof uses real data and advanced analytics to help you make informed betting decisions. Get access to professional-grade predictions for NFL, College Football, and more.
Get Started Free