
Ultimate Guide to Real-Time Sports Data Aggregation
Real-time sports data aggregation is the process of collecting and delivering live updates on matches, player stats, and betting odds from multiple sources into a unified feed. This technology is vital for sports betting, where even a few seconds’ delay can lead to poor decisions. Advanced systems now provide updates in under 15 seconds, often faster than live TV broadcasts, and cover thousands of leagues globally.
Key points include:
- Speed and accuracy are critical: Live odds shift rapidly due to gameplay, injuries, or trends. Systems use WebSockets and streaming feeds for millisecond updates.
- Data sources: APIs, prediction markets, public betting data, contextual insights like weather, and player stats.
- Technologies: Event-driven architectures (e.g., Apache Kafka, Redis), real-time processing tools, and cloud-based synchronization ensure low latency and reliability.
- Challenges: Normalizing data across providers, managing latency, duplicates, and scaling systems for high traffic.
- Actionable insights: Tools like WagerProof use AI for edge detection, simulations, and real-time alerts to help bettors make informed decisions.
This guide explores how real-time sports data aggregation transforms raw data into actionable betting insights, leveraging advanced technology and AI tools to stay ahead in the fast-paced betting industry.
Primary Data Sources for Sports Aggregation
Live Sports APIs and Data Feeds
Live sports APIs deliver essential updates like scores, player stats, injury news, and play-by-play details for major U.S. leagues.
When it comes to these services, reliability is key. Providers like Balldontlie ensure 99.9% uptime and round-the-clock support. Their pricing is tiered, starting with a free plan (allowing 5 requests per minute) and scaling up to an All-Access plan at $499.99/month, which covers over 20 sports and supports 600 requests per minute. To streamline updates, webhooks are used to send instant notifications for events, removing the need for constant manual polling.
While live feeds are foundational, other data sources add valuable insights to the mix.
Prediction Markets and Public Betting Data
Prediction markets operate on a peer-to-peer model where prices shift based on supply and demand. This creates a dynamic data source that reflects collective intelligence rather than the traditional risk management approach used by bookmakers.
Public betting data, such as bet percentages and money lean, provides further insights. It highlights where professional bettors (sharp money) are placing their bets compared to the general public. Platforms like WagerProof compile this data alongside prediction market trends, flagging discrepancies and surfacing potential value bets. For example, when prediction market spreads differ from sportsbook odds, bettors gain a clearer picture of where opportunities might lie.
These market-driven signals, when combined with other data, offer a more holistic view for betting decisions.
Additional Data Sources
Contextual data, like weather and player trends, adds depth to analysis. For outdoor sports, weather conditions can significantly impact gameplay - NFL passing games may be affected by wind speed, while MLB home runs could decrease in colder temperatures. Player metrics, such as shooting percentages, recent performance, and matchup history, also provide critical context. Historical data, meanwhile, can shed light on line movements and reveal patterns over time.
The timing of data updates varies by sport. Sometimes, post-game corrections can take days to finalize, requiring continuous tracking. Successful aggregation systems must account for the entire lifecycle of data, from pre-game rosters to post-event adjustments.
Seamlessly integrating these diverse sources is crucial for delivering accurate and timely betting insights.
Engineering Real-Time Sports Trading at Global Scale
Technologies and Methods for Data Integration
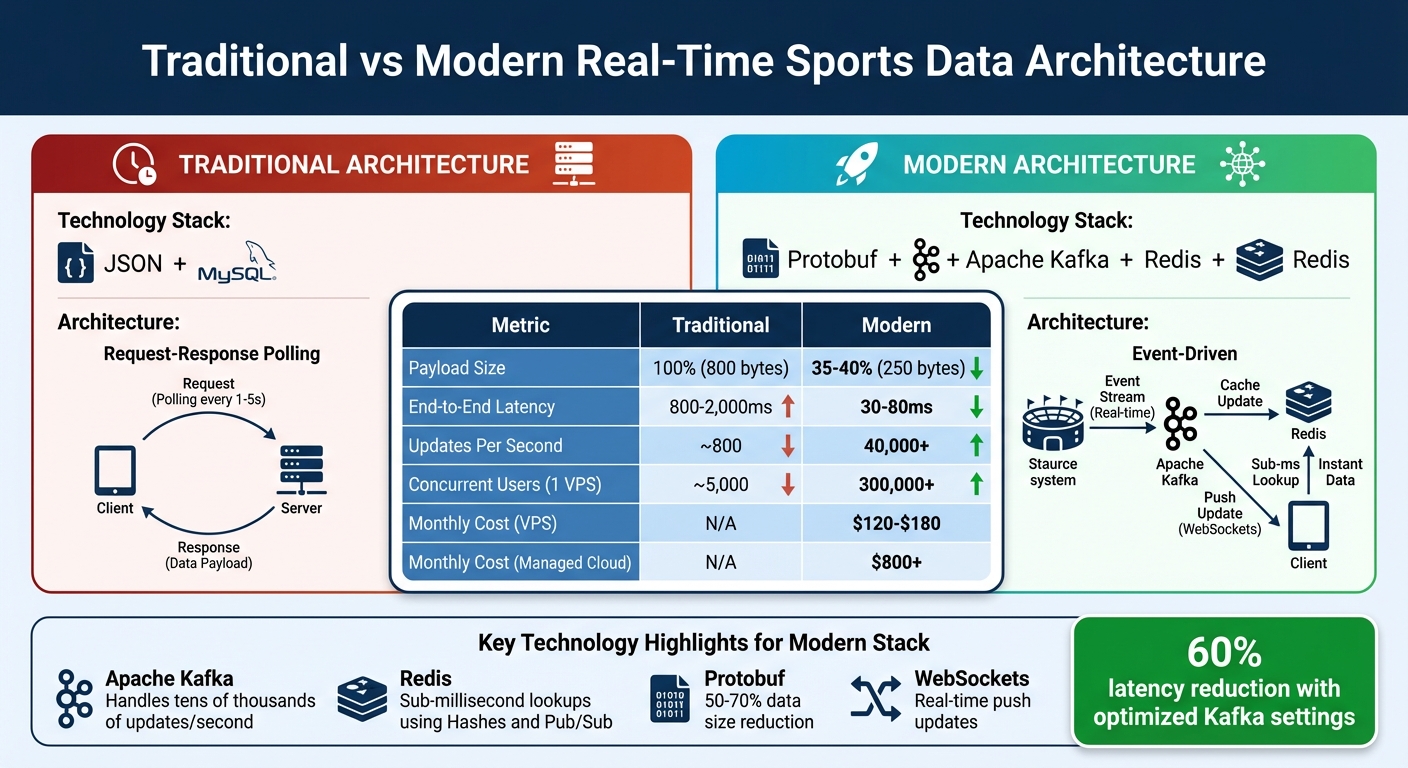
Traditional vs Modern Real-Time Sports Data Architecture Performance Comparison
Event-Driven Architectures for Real-Time Updates
Modern sports data platforms rely on event-driven systems rather than the old request-response polling methods. Apache Kafka is a key player here, handling tens of thousands of updates per second from providers like Sportradar and Genius Sports without missing a beat. This setup separates data providers from consumers, ensuring that if one part fails, it doesn’t crash the entire system.
In this architecture, Redis plays a crucial role. It uses Hashes for lightning-fast lookups (sub-millisecond speeds) and Pub/Sub to instantly push updates via WebSockets. For instance, an 8-vCPU NVMe VPS can support over 300,000 concurrent users with ultra-low latency, costing just $120–$180 per month. Compare this to managed cloud services, which can run upwards of $800 per month.
"As Rendy notes, real-time odds depend on reliable data plumbing."
Optimizing payloads is another game-changer. Switching from JSON to Protobuf slashes data size by 50–70%, reducing an 800-byte payload to around 250 bytes. To minimize latency, tweak Kafka settings (linger.ms=0 and fetch.min.bytes=1) to capture data instantly, cutting latency by about 60%.
| Metric | Traditional (JSON + MySQL) | Modern (Protobuf + Kafka + Redis) |
|---|---|---|
| Payload Size | 100% | 35–40% |
| End-to-End Latency | 800–2,000ms | 30–80ms |
| Updates Per Second | ~800 | 40,000+ |
| Concurrent Users (1 VPS) | ~5,000 | 300,000+ |
Source:
For peak performance, make some system-level adjustments. Update /etc/sysctl.conf to set net.core.somaxconn to 65,535 and enable TCP BBR to manage heavy WebSocket traffic. Adjust vm.swappiness=0 to prevent swap events from spiking latency from 20ms to 800ms. Additionally, pin Kafka brokers and Redis instances to specific CPU cores using tools like taskset or numactl to eliminate jitter during high-traffic events, such as the Super Bowl.
With these event-driven strategies in place, cloud-based synchronization ensures data consistency on a global scale.
Cloud-Based Sync and Cross-Platform Integration
Cloud synchronization keeps data consistent across devices and platforms. By deploying data nodes closer to users with AWS Local Zones or Cloudflare Workers, global latency is significantly reduced.
Technologies like WebSockets and gRPC have made traditional REST polling obsolete for live sports updates. These tools deliver real-time updates with no lag, which is critical for the next generation of sports APIs, expected to prioritize real-time delivery, low latency, and detailed data by 2026.
For real-time processing, tools like Apache Flink, ksqlDB, and Spark Structured Streaming are used to normalize and enrich data while detecting arbitrage signals. These systems aim to deliver updates to users' screens within 100ms of the physical event.
These synchronization methods lay a strong foundation for effective API integration.
API Integration Best Practices
To ensure timely and accurate betting insights, optimized API integration is essential. Start by normalizing all incoming odds formats - American, Fractional, Decimal - into a single decimal format right after ingestion.
Sequence-number tracking is vital for identifying dropped or out-of-order messages. Modern pipelines often include nanosecond timestamps, requiring aggregators to implement sequence IDs for proper ordering. Use exponential backoff and per-source rate limiting to manage client requests effectively.
Error handling is another critical area. Synchronize ingestion nodes using NTP/PTP and record both the provider timestamp (source_ts) and the arrival time (ingest_ts) for accurate audits. Include a manual kill-switch and automated rate-limiters to prevent losses during data spikes or errors. When interacting with APIs, use the include=available query parameter to speed up payloads by excluding expired or unlisted markets.
Common Challenges in Data Aggregation
Data Normalization Across Multiple Sources
Aggregating sports data isn't as simple as it sounds - each provider structures their feeds differently, requiring sport-specific adjustments. For instance, golf tournaments organize players at the "Betting Outcome" level, unlike team sports, which often use the "Betting Market" level. This means creating normalization rules tailored to each sport.
Timing complicates things further. NFL player props typically appear 72–96 hours before kickoff, but MLB and NHL props might only show up 24–48 hours before game time. Trying to synchronize data from sources with such varying schedules can be a real challenge.
Then, there are stat corrections. NFL statistics, for example, can change days after a game ends. To capture these updates, your system must refresh data for 48–72 hours post-game. And don't forget about market suspensions - odds may temporarily disappear and then reappear with the same values. Your normalization process needs to track these as new records with unique timestamps to keep an accurate audit trail.
"In 2026, the defensible edge is not just the model - it's the quality and lineage of your structured data." - Scrapes.Us
To tackle these issues, building canonical schemas is key. These schemas - structured production tables like Games, Plays, Lines, Predictions, and Outcomes - should include proper primary and foreign keys. For complex markets like Golf "SixShooters", using a "GroupKey" to connect related outcomes within a sportsbook grouping can reduce ambiguity and prepare your data for AI applications.
Once normalization is in place, the next hurdle is managing latency and duplicates.
Managing Data Latency and Duplicates
Latency can cost you. If odds shift before your data is processed, you might miss out on profitable betting opportunities. Even worse is lookahead bias - when historical predictions are merged with outcomes incorrectly, creating unrealistic results. This often happens when timestamps aren't normalized to UTC or when event-driven snapshots are out of sequence.
Duplicate entries add another layer of trouble. Raw JSON feeds often include redundant records, which, if left unchecked, can distort averages and skew predictive models. Even a single duplicate can throw off your analysis.
| Challenge | Impact on Betting Models | Mitigation Strategy |
|---|---|---|
| Data Latency | Missed opportunities; lookahead bias | Event-driven ingestion (Kafka); Caching (Redis); Stream processing |
| Duplicate Entries | Skewed stats; increased processing load | Canonical schema design; Deduplication during ETL/ELT |
| Timestamp Mismatch | Poor event-odds correlation | UTC normalization; Event-driven snapshots |
To avoid these pitfalls, convert all incoming data to UTC and use event-driven snapshots to ensure proper event sequencing. Tools like Redis can cache frequently accessed data, such as live scores, to improve response times.
With latency and duplication under control, the next challenge is building systems that can scale effectively.
Building Scalable and Reliable Systems
Once you've solved normalization and timing issues, the focus shifts to scaling your infrastructure to handle the real-time demands of sports data. Vertical scaling has its limits, so horizontal scaling is the way to go. Pairing it with WebSocket or streaming integrations can reduce the bottlenecks caused by REST polling.
System reliability is just as important. To offset the risk of provider outages, onboard at least two independent providers for high-value markets. A weighted consensus approach, like using weighted medians, can help reconcile conflicting data points. For example, in January 2026, some publishers faced sudden revenue shocks, losing up to 90% of their AdSense revenue overnight, which led to throttled APIs. Relying on a single ad-funded source could leave your system vulnerable to similar disruptions.
Delta APIs, which return only updated stats, are another useful tool. They reduce payload sizes and speed up integration - especially during live games, when stats are updated frequently.
Using an API gateway like Apache APISIX can also streamline operations. It manages traffic, securely injects API keys, and enables intelligent caching for semi-static data like rosters and schedules. During times of high market fluctuations or provider instability, features like "age-of-data" and confidence scores can help users understand when data might be outdated.
The shift to cloud-based data integration is undeniable, now dominating 65% of the market. Streaming Change Data Capture (CDC) is gradually replacing traditional batch ETL for applications needing sub-second latency. Betting data systems relying on nightly batch jobs are quickly falling behind.
Turning Aggregated Data into Betting Insights
Creating Multi-Model Consensus for Betting Decisions
Raw data on its own doesn’t cut it - you need to shape it into meaningful predictive signals. This is where feature engineering comes in. For example, you can calculate 5-game or 10-game rolling averages to reflect recent performance trends, adjust metrics based on the quality of opponents to normalize results, or incorporate situational factors like travel distance or rest days to refine predictions.
Once you’ve engineered these features, the next step is aggregation. You can use methods like weighted averaging, Z-score standardization, or median aggregation to combine predictions:
- Weighted averaging prioritizes models with proven accuracy but requires detailed tracking of past performance.
- Z-score standardization adjusts for variance in predictions, though it involves more complex statistical steps.
- Median aggregation helps filter out extreme outliers but might miss nuanced insights from niche models.
The margin for consistent success in against-the-spread (ATS) betting is razor-thin, typically between 55% and 57% accuracy. Even minor improvements in your consensus methods can have a big impact on long-term profitability. By early 2026, the betting world is leaning more toward specialized tabular foundation models, which rely on well-structured, high-quality data. In short, the better your data aggregation, the stronger your multi-model consensus - and that consensus becomes the backbone of the real-time analysis offered by WagerProof's AI tools.
Using WagerProof AI Tools for Edge Detection
With a strong consensus in place, WagerProof’s AI tools take things to the next level. These tools are designed to turn aggregated data into actionable betting insights, thanks to continuous analysis and automated edge detection.
- The Edge Finder compares predictions from multiple models against current market odds, uncovering opportunities where value bets exist and highlighting gaps in consensus.
- The AI Game Simulator runs thousands of simulations for each game, creating win probability percentages. These probabilities help identify value bets when they differ significantly from sportsbook lines.
Then there’s WagerBot Chat, a game-changer in sports betting. It’s the only AI connected to live professional data that delivers clear, straightforward analysis. You can ask it questions like, “Should I bet the over in tonight’s Lakers game?” and get a detailed response. It pulls together weather conditions, injury reports, market odds, and model predictions into one easy-to-understand recommendation.
WagerProof also offers the Public Money Splits tool, which tracks the percentage of tickets versus money on each side of a bet. This tool exposes gaps between sharp bettors (professionals) and public betting trends, often pointing to where the value lies.
WagerProof's AI agents work around the clock, each tailored with specific risk levels, sport preferences, and betting styles across 50+ adjustable parameters. Their results are fully transparent - no hidden data or manipulated records. This constant monitoring ensures you don’t miss out when market conditions shift or when unexpected opportunities arise in live betting.
Automating Outlier Detection and Alerts
To complement its consensus models and edge-detection tools, WagerProof uses automated systems to spot anomalies in real time. Manual monitoring is slow and prone to errors, but automation ensures no valuable data slips through the cracks.
For example, when WagerProof's algorithms detect mismatches between prediction market spreads and sportsbook lines, they send instant alerts. These mismatches often signal value bets, giving you a chance to act before the market adjusts.
Automated systems also flag fade alerts, which occur when public betting is heavily skewed in one direction, but professional money moves the other way. This happens when a high percentage of tickets are on one side, but the majority of money is placed on the opposite side - indicating that sharp bettors see an edge against public opinion. These alerts give you a critical advantage in live betting, helping you capitalize on profitable opportunities in seconds.
Conclusion
Real-time sports data aggregation is the backbone of smarter betting strategies. When live scores, odds changes, injury updates, and prediction markets are consolidated into one reliable source, bettors can avoid making decisions based on outdated information. Modern systems now deliver live updates in under 200 milliseconds - a game-changer for in-play betting, where even a short delay can mean the difference between seizing an opportunity or missing out entirely.
The real challenge lies not just in gathering data but in transforming it into actionable insights. Advanced techniques like multi-model consensus, feature engineering, and automated outlier detection convert raw numbers into meaningful betting advantages. This process is further enhanced by AI-driven tools that refine strategies and improve decision-making. For instance, WagerProof offers AI research agents that work tirelessly, analyzing matchups and delivering picks with full transparency. Their WagerBot Chat streamlines the betting process by merging diverse data sources into clear, data-backed recommendations.
By combining real-time data feeds with cutting-edge analytics, bettors gain a level of insight that elevates competitive play. A notable example of this innovation occurred in December 2025, when a live betting platform adopted a WebSocket-based push system, slashing latency from 5 seconds to under 200 milliseconds.
Access to fast and accurate data is crucial for staying ahead in the betting world. WagerProof delivers that edge, equipping bettors with transparent tools, high-quality data, and AI-powered analysis to make smarter, more informed wagers.
FAQs
How do you verify live odds are actually real-time?
To make sure live odds are truly in real-time, rely on a trusted sports odds API that provides frequent updates and includes clear timestamps for each change. Always cross-check these odds with other live sources or directly with sportsbooks to confirm their accuracy. Timestamps are crucial - they show that the data aligns with current market movements, which is key for accurate sports betting analysis.
What’s the best way to dedupe and order out-of-sequence updates?
To manage updates that arrive out of sequence, set up a time-based buffer to temporarily store incoming data. This buffer provides a window for late updates to catch up. Arrange the data by timestamps to maintain the correct chronological order. Use a versioning system to eliminate duplicates and ensure only the most recent updates are processed. Once the buffer's time window closes, release the data in sequence, ensuring accurate real-time analytics.
How can WagerProof turn raw feeds into betting edges fast?
WagerProof takes raw sports data feeds and turns them into actionable betting opportunities. By combining multiple sources - like official league feeds, real-time odds, and historical data - it delivers a comprehensive view of the betting landscape. Its AI tools dive into live data, including factors like weather, player injuries, and market shifts, to uncover inefficiencies such as mismatched odds. With automated alerts and edge detection, users can quickly act on these insights, seizing profitable chances before the market catches up.
Related Blog Posts
Ready to bet smarter?
WagerProof uses real data and advanced analytics to help you make informed betting decisions. Get access to professional-grade predictions for NFL, College Football, and more.
Get Started Free