
Statistical Models vs. Machine Learning in Betting
Sports betting has evolved from basic statistical methods to advanced machine learning (ML) models. Both approaches aim to predict game outcomes and find value bets but differ in methodology, data needs, and flexibility.
Key Takeaways:
- Statistical Models: Use fixed formulas (e.g., regression, Poisson distribution) to calculate probabilities. They're simple, transparent, and work well with smaller datasets but struggle with real-time updates and complex patterns.
- Machine Learning: Leverages algorithms like Random Forests and Neural Networks to analyze large, diverse datasets. It excels at identifying hidden patterns and adapting to new data but often lacks transparency and requires significant computing power.
Performance Insights:
- Calibration (aligning predicted probabilities with actual outcomes) is more important than accuracy. Models focused on calibration delivered a +34.69% ROI, while accuracy-focused models led to losses.
- ML models can process thousands of variables, offering a deeper analysis of player stats, betting trends, and real-time data, outperforming statistical models in complex scenarios.
When to Use Each:
- Statistical Models: Best for pre-game bets and straightforward analyses where clarity is vital.
- Machine Learning: Ideal for live betting, large datasets, and uncovering inefficiencies in bookmaker odds.
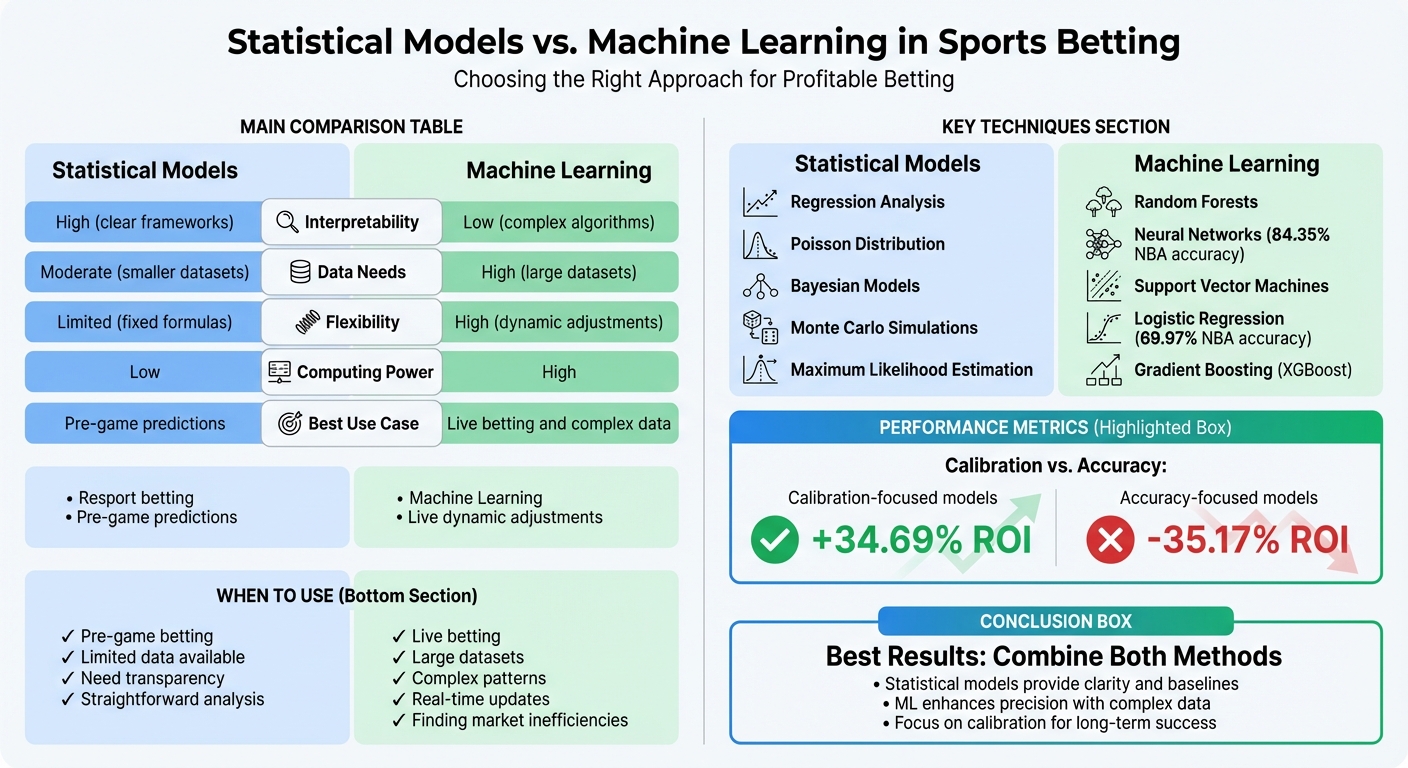
Quick Comparison:
| Factor | Statistical Models | Machine Learning |
|---|---|---|
| Interpretability | High (clear frameworks) | Low (complex algorithms) |
| Data Needs | Moderate (smaller datasets) | High (large datasets) |
| Flexibility | Limited (fixed formulas) | High (dynamic adjustments) |
| Computing Power | Low | High |
| Best Use Case | Pre-game predictions | Live betting and complex data |
Conclusion: Combining both methods often yields the best results. Statistical models provide clarity and strong baselines, while ML enhances precision by processing complex data. Calibration-focused strategies are critical for long-term betting success.
Statistical Models vs Machine Learning in Sports Betting: Complete Comparison
I Trained AI to Predict Sports
Statistical Models Explained
Statistical models in sports betting rely on mathematical formulas to estimate the "true" probability of a game outcome. This probability, expressed as a value between 0 and 1, reflects how likely a team is to win. If your model's calculated probability is higher than the bookmaker's implied probability, it may signal a value betting opportunity.
These models often use techniques like Maximum Likelihood Estimation (MLE) to derive team strength ratings based on historical win/loss records and scoring data. Mapping functions, such as power or logistic functions, are then applied to ensure probabilities stay within the valid range of 0 to 1. This structured approach ensures predictions remain mathematically sound.
However, statistical models depend heavily on robust datasets for accuracy. For example, estimating an 80% win probability based on just one game is unrealistic because the actual outcome is binary - either 100% for a win or 0% for a loss. Limited historical data can lead to unreliable predictions, and circular outcomes (e.g., Team A beats B, B beats C, and C beats A) present additional challenges for these methods.
Common Statistical Techniques
Several techniques help bring statistical models to life, each tailored to different aspects of prediction:
Regression Analysis:
This method identifies key variables, such as player injuries or weather conditions, that significantly impact outcomes. It allows models to adjust predictions based on changing circumstances.
Poisson Distribution:
Ideal for predicting discrete events like goals in soccer or points in basketball, the Poisson distribution is widely used. Advanced versions, like the Dixon-Coles model, add depth by estimating separate attack and defense parameters for teams and weighting recent performances more heavily.
Bayesian Models:
Bayesian approaches excel at managing uncertainty. They can update probabilities in real time as new information - like a last-minute player injury - becomes available.
Monte Carlo Simulations:
These simulations run thousands of game iterations, generating a range of possible outcomes instead of a single prediction. This helps bettors understand potential risks and assess the variability of results.
| Technique | Application | Benefit |
|---|---|---|
| Regression Analysis | Adjusting for variables like injuries or weather | Highlights impactful factors |
| Poisson Distribution | Modeling goals or points scored | Suited for discrete-event prediction |
| Bayesian Models | Incorporating real-time updates | Handles uncertainty effectively |
| Monte Carlo Simulations | Simulating multiple outcomes | Offers a broader risk assessment |
| Maximum Likelihood Estimation | Rating team strength from historical data | Effective with limited head-to-head data |
Pros and Cons of Statistical Models
One of the standout features of statistical models is their transparency. Unlike machine learning's "black box" nature, these models clearly show why a prediction leans one way - whether it's due to a team's strong offense, home advantage, or favorable history against an opponent.
They’re also accessible for beginners. Many bettors start with simple models in Excel or Google Sheets, using basic probability formulas and historical data. These tools don’t require vast datasets or advanced software to get started.
That said, statistical models have limitations. Their reliance on constant linear relationships can struggle to capture the complexities of sports, where dynamics change rapidly. They’re also sensitive to data quality; for instance, an undefeated team with an easy schedule might be overrated by a basic model. Additionally, these models typically require manual updates, making them slow to adapt to sudden changes like player injuries or lineup shifts.
"A probability model is defined as a mathematical representation that links physical theories to random variables, utilizing appropriate distributions and dependency relations to describe and predict variability in observed data."
– International Geophysics
Grasping these fundamentals provides a solid foundation for comparing statistical models with more adaptive machine learning techniques.
Machine Learning in Sports Betting
Machine learning doesn’t rely on fixed formulas. Instead, it identifies patterns from vast amounts of data, analyzing thousands of variables at once. This allows it to pick up on subtle factors - like referee tendencies, team travel schedules, or weather conditions - that simpler models might miss entirely. This ability to account for complex interactions has led to a variety of machine learning algorithms, each tailored to handle this intricate data landscape.
The transition from traditional statistical methods to machine learning isn’t just about technology - it’s a shift in approach. While statistical models emphasize clarity and interpretability, machine learning focuses on recognizing patterns on a massive scale. By processing enormous datasets and adjusting to new information, these algorithms help remove emotional bias from decision-making. This adaptability is a cornerstone of modern betting analytics and aligns closely with the data-driven strategies used by platforms like WagerProof.
Popular Machine Learning Algorithms
Some machine learning algorithms have proven particularly effective in sports betting, each offering distinct advantages:
- Random Forests: These models combine multiple decision trees to make predictions, helping them handle outliers well and identify which variables are most important. For instance, they can determine whether home-court advantage or recent performance has more influence.
- Neural Networks: Advanced types like Multi-Layer Perceptrons (MLPs) and Convolutional Neural Networks (CNNs) excel at uncovering non-linear relationships in data. One CNN model using player-level stats achieved 84.35% accuracy for NBA predictions, outperforming models that relied solely on team-level data (80% accuracy).
- Support Vector Machines (SVMs): These models are great for binary classifications, such as predicting wins or losses, by finding the optimal boundary in multi-dimensional data.
- Logistic Regression: Despite being simpler, this algorithm often delivers solid results. In one study, it achieved 69.97% accuracy on NBA data, outperforming more complex models.
- Gradient Boosting: Algorithms like XGBoost refine predictions by correcting errors in each iteration, making them highly accurate for sports like tennis and basketball.
| Algorithm | Primary Application | Key Strength |
|---|---|---|
| Random Forests | Outcome classification and feature importance | Handles high-dimensional data effectively |
| Neural Networks | Complex pattern detection from player-level stats | Captures non-linear relationships |
| Support Vector Machines | Binary win/loss prediction | Effective in multi-dimensional spaces |
| Logistic Regression | Probability estimation baseline | High transparency and strong ROI potential |
| Gradient Boosting | Value bet identification | Superior accuracy through iterative learning |
Machine Learning Advantages and Drawbacks
One of machine learning’s biggest strengths is its ability to process massive datasets at lightning speed. Where manual analysis might focus on a dozen key metrics, ML algorithms can analyze thousands of variables simultaneously, even delivering real-time alerts when odds shift.
Another advantage is its knack for spotting market inefficiencies - areas where odds don’t align with actual probabilities. However, machine learning isn’t without its challenges. The most notable is the "black box" problem. Unlike traditional statistical models, it’s often unclear why a neural network makes a specific prediction. This lack of transparency can make it hard to trust or validate results.
Additionally, machine learning models require significant computing power and large datasets to perform well, creating hurdles for casual bettors. Even with these advanced tools, prediction accuracy often falls between 50% and 60%, and even the top-performing models rarely exceed 70% accuracy in professional sports like tennis.
"A highly accurate predictive model is useless as long as it coincides with the bookmaker's model."
– Hubáček et al.
The real challenge isn’t just predicting outcomes - it’s identifying predictions that differ meaningfully from bookmaker odds while still being accurate enough to generate long-term profits.
Statistical Models vs. Machine Learning: Main Differences
Side-by-Side Comparison
Statistical models and machine learning approach betting challenges in distinct ways. Statistical models rely on probability distributions and theoretical frameworks - like using Poisson regression to predict scores. Machine learning, on the other hand, emphasizes classification and pattern recognition across vast datasets.
In betting, success isn’t just about accuracy; it’s about calibration - ensuring predicted probabilities align with actual outcomes. For instance, an NBA study revealed that calibrated models delivered a +34.69% ROI, while accuracy-focused models resulted in a –35.17% loss.
| Factor | Statistical Models | Machine Learning |
|---|---|---|
| Interpretability | High; grounded in clear mathematical frameworks (e.g., Poisson) | Lower; often involves "black box" models like Neural Networks |
| Flexibility | Limited; bound by theoretical assumptions | High; adapts to complex, non-linear patterns in data |
| Data Needs | Moderate; works well with smaller, structured datasets | High; thrives on large volumes of historical and live data |
| Computing Requirements | Low to moderate; uses batch processing | High; demands significant resources for training and real-time inference |
| Primary Use Case | Predicting outcomes or scores (e.g., Poisson for soccer) | Handling complex markets and live betting scenarios |
These differences highlight where each method excels depending on the context.
Best Use Cases for Each Method
The choice between statistical models and machine learning depends heavily on the betting situation. Statistical models are well-suited for straightforward pre-game bets, especially when understanding how individual variables impact outcomes is critical. For example, a Poisson distribution effectively captures goal-scoring patterns in soccer. If clarity and transparency are priorities, statistical models provide a solid, reliable approach.
Machine learning shines in more intricate scenarios. It handles massive, multi-dimensional datasets - like player box scores from thousands of games - that go beyond what traditional models or human analysis can manage. Its ability to process real-time data makes it ideal for live betting, where odds shift constantly, and quick adjustments are essential.
Ultimately, the goal isn’t just to build an accurate model but to identify where your predictions differ from the bookmaker's odds. The real advantage lies in spotting inefficiencies that conventional methods might overlook.
Performance Results in Sports Betting
Accuracy and ROI Results
Betting success isn’t just about making accurate predictions - it’s about how those predictions are used in wagering strategies. A 2020 study from UCLA, led by researcher Guy Dotan, tested several machine learning models - logistic regression, random forest, XGBoost, and neural networks - on NBA box score data from 2007 onward. All four models achieved prediction rates exceeding 60% for NBA game winners. For the 2019–20 season, a logistic regression model yielded a 5% ROI using fixed wagering. However, when Dotan applied a fractional Kelly strategy (known as "5th Kelly"), ROI skyrocketed to approximately 98%.
"Using our best fixed wagering technique, we were able to generate a return on investment of about 5% over the course of the entire season. Using... the Kelly criterion... we were able to almost double our investment with a return of about 98%."
– Guy Dotan, UCLA
Further research from the University of Bath in 2024 by Conor Joseph Walsh and Alok Joshi highlighted the importance of how models are selected. Models optimized for calibration achieved an average ROI of +34.69%, while those chosen purely for accuracy averaged a significant loss of 35.17%. In the best cases, calibration-focused models reached a +36.93% ROI, compared to just +5.56% for the most accurate models. This underscores the importance of aligning wagering strategies with a model's calibration to achieve long-term profitability.
Neural networks, known for their high performance, can exceed 84% prediction accuracy. However, profitability depends on factoring in the bookmaker’s margin, as even highly accurate models can falter without this consideration. These findings set the stage for exploring how performance metrics vary across different sports.
Performance Across Different Sports
The effectiveness of prediction models varies significantly by sport. In NBA basketball, the abundance of data, frequent games, and dynamic player interactions give machine learning models a distinct edge, leading to high prediction accuracy rates.
In tennis, however, prediction accuracy tends to plateau around 70%. Despite this, long-term betting returns are often negative, reflecting the efficiency and volatility of tennis betting markets.
"Returns from applying predictions to the sports betting market [in tennis] are subject to high volatility and mainly negative over the longer term."
– Sascha Wilkens, Independent Researcher
For soccer, traditional statistical approaches like Poisson regression remain effective. At the same time, machine learning methods, such as Random Forest, are increasingly used to process the sport's massive and intricate datasets. Each sport presents unique challenges and opportunities for applying predictive models, shaping how strategies are developed and executed.
Choosing the Right Approach for Your Betting
When to Use Statistical Models
Statistical models shine when clarity and simplicity are essential, especially if you're working with limited data. For example, with just a single season's box scores or basic team stats, tools like Poisson regression or Dixon-Coles can deliver reliable predictions without demanding heavy computing power. These models are particularly suited for pre-game betting, where analysis is based on historical data and closing odds rather than real-time updates.
The biggest advantage of statistical models is their interpretability. They focus on essential game dynamics, making it easier for bettors to understand and refine their strategies. This approach works well for sports like soccer, where traditional methods remain effective. If you're looking for a straightforward, manageable way to build a betting strategy, statistical models provide a solid foundation without the added complexity of machine learning.
When to Use Machine Learning
Machine learning is your go-to when you're dealing with large datasets and fast-changing conditions. It's perfect for analyzing high-volume prop bets, live odds that shift in real-time, or spotting inefficiencies across hundreds of games. Algorithms like Random Forest and neural networks excel at uncovering hidden, non-linear patterns in the data. For instance, a Random Forest model predicting MLB hits reached 61% precision, showcasing how ML can extract insights from detailed player-level data.
One of the key strengths of ML models is their ability to compare calibrated probabilities against bookmaker odds, helping you identify mispriced outcomes - situations where the actual probability of an event is higher than what the odds suggest. However, this approach comes with higher demands. Live betting, for example, requires real-time data processing, which is far more resource-intensive than the batch processing used for pre-game analysis. If you have access to robust data and computational resources, machine learning can help uncover opportunities that simpler methods might miss.
Using WagerProof's Combined Approach
For those wanting the best of both worlds, WagerProof offers an integrated solution that combines statistical models with machine learning. This platform identifies outliers and value bets by comparing prediction market spreads, statistical baselines, and ML-generated probabilities in real-time. When discrepancies arise - say, when prediction markets suggest one spread but statistical models point to another - WagerProof flags these as potential opportunities.
WagerProof's hybrid approach tackles calibration issues to improve ROI. It blends historical stats, public betting data, and money lean indicators to pinpoint where bookmakers might have mispriced outcomes. Additionally, the platform's WagerBot Chat connects you to live professional data, allowing you to access real-time insights without the inaccuracies often found in standard AI tools. By combining the transparency of statistical models with the adaptability of machine learning, WagerProof empowers you to execute advanced betting strategies seamlessly across web, iOS, and Android platforms. Whether you lean toward statistical clarity or ML's pattern recognition, WagerProof equips you with the tools to optimize your betting game.
Combining Both Methods and Future Trends
Using Statistical Models to Improve Machine Learning
The most effective betting strategies seamlessly blend statistical models with machine learning (ML). Statistical methods are particularly adept at creating "Adjusted Ratings", which factor in elements like league quality and home-field advantage. These ratings serve as high-quality inputs for machine learning algorithms, enhancing their predictive capabilities.
By combining the interpretability of statistical models with the predictive strength of ML, bettors can address the limitations of using either method alone. A noteworthy example is a June 2024 study, which revealed that models calibrated for better predictions achieved a +34.69% ROI, whereas those optimized solely for accuracy resulted in a –35.17% ROI.
Another effective strategy involves pairing ML-generated probabilities with decision-making frameworks like the Kelly Criterion or Modern Portfolio Theory. For instance, a 2019 study demonstrated that a "5th Kelly" approach achieved an ROI exceeding 98%, balancing returns with variance. Furthermore, statistical methods can decorrelate ML outputs from bookmaker odds - often adjusted by a 2.5%–5% margin - allowing bettors to identify genuine value bets. This combination not only improves calibration but also enables dynamic, real-time betting adjustments.
What's Next in Sports Betting Analytics
The future of betting analytics is moving toward integrating multimodal data - combining real-time in-game stats, video feeds, and textual data into unified predictive systems. This shift allows models to go beyond static data, dynamically adjusting predictions as games progress. This advancement is particularly transformative for live betting, where conditions change moment-to-moment.
Another emerging trend is the "financialization" of betting. This approach treats wagers as part of a diversified portfolio, applying Modern Portfolio Theory to balance expected returns and risks across multiple games. Additionally, AI-driven fraud detection is becoming a critical tool, leveraging anomaly detection to flag unusual betting patterns and identify potential match-fixing.
The analytics field is also pivoting from team-level forecasts to player-centric models. These advanced systems assess individual player performance and interactions, offering more detailed insights into team strength. Unlike traditional team averages, these models capture subtle dynamics that can significantly impact outcomes.
For bettors looking to gain an edge, the key takeaway is to prioritize calibration over raw accuracy when evaluating predictive models. Metrics such as the Brier score and Expected Calibration Error (ECE) provide a clearer picture of a model's true predictive performance than simple win/loss accuracy metrics. Additionally, incorporating domain knowledge - like understanding player roles or variations in league strength - consistently outperforms strategies that rely solely on algorithmic outputs.
"Machine learning algorithms have the unattractive property of not representing reality... incorporating domain knowledge in forecasting models is a key driver of success" – Ian G. McHale, Professor of Analytics
Platforms like WagerProof are already ahead of the curve, combining statistical baselines with ML-generated probabilities to flag outliers and uncover value bets in real time. By integrating prediction markets, historical data, and public betting trends, WagerProof identifies mispriced outcomes, paving the way for more profitable sports betting analytics.
Conclusion
Statistical models and machine learning each bring unique strengths to sports betting, but neither can dominate on its own. Statistical methods provide clarity and reliable baseline predictions, while machine learning excels at analyzing complex, player-specific data and uncovering non-linear patterns. The true advantage lies in combining these approaches - using statistical models as strong inputs for machine learning algorithms while focusing on calibration and managing risk effectively. This calibration-first strategy is key to understanding how to capture value in betting markets.
Profitability in betting isn't just about accuracy - it’s about calibration. Research highlights this starkly: calibrated models delivered a +34.69% ROI, while accuracy-centered models resulted in a -35.17% loss. As Walsh aptly put it:
"Sports bettors who wish to increase profits should therefore select their predictive model based on calibration, rather than accuracy"
The real value lies in spotting gaps between model predictions and bookmaker odds, often in the 2.5%–5% range. This requires tools capable of identifying these opportunities in real time.
Platforms like WagerProof showcase how this approach works in practice. By integrating statistical foundations with machine learning-driven probabilities, WagerProof flags outliers and value bets across prediction markets, historical data, and public betting trends. Instead of offering vague recommendations, it provides clear, data-backed insights to help bettors identify value - whether through mismatched spreads, fade signals, or predictions that deviate from bookmaker odds. With tools like WagerBot Chat, which connects users to live professional data and expert picks curated by Real Human Editors, bettors receive both advanced analytics and actionable insights. This blend of robust data and real-time guidance empowers bettors to consistently spot and capitalize on market inefficiencies.
FAQs
What’s the difference between statistical models and machine learning in sports betting?
Statistical models and machine learning take different approaches when it comes to predicting outcomes in sports betting.
Statistical models stick to traditional methods like regression analysis or Bayesian techniques. These rely on historical data and predefined assumptions to uncover relationships between variables. They’re rooted in well-established statistical theories, making them straightforward and easier to interpret.
In contrast, machine learning leans on algorithms such as neural networks or random forests to analyze massive datasets, often including real-time stats. These models shine at spotting intricate patterns and can adjust to new data automatically - no manual tweaks needed. While statistical models offer more transparency, machine learning often delivers greater accuracy and better calibration, which can make a big difference when making smarter betting choices.
Why is calibration more valuable than accuracy in sports betting models?
In sports betting, calibration plays a key role in evaluating a model's reliability. It measures how closely a model's predicted probabilities match the actual outcomes. For example, if a model predicts a 70% chance of winning, calibration ensures that this figure genuinely represents a 70% likelihood. This alignment is critical for making well-informed betting choices.
While accuracy focuses on how often predictions are correct, calibration digs deeper by assessing whether the probabilities themselves are meaningful. This distinction is vital for spotting value bets, managing risks effectively, and maintaining profitability over time. By prioritizing calibration, bettors can place greater trust in a model’s predictions and make smarter, data-driven decisions.
When is it better to use machine learning instead of statistical models for sports betting?
Machine learning tends to shine when your betting strategy involves detecting intricate patterns or relationships hidden within large datasets - patterns that traditional statistical models might overlook. It’s particularly effective in handling dynamic variables and, when fine-tuned, can lead to more accurate probability predictions, potentially boosting profitability.
However, statistical models can still be the better option for straightforward, well-defined analyses or when dealing with smaller datasets. The decision really comes down to the complexity of your data and the specific objectives of your betting approach.
Related Blog Posts
Ready to bet smarter?
WagerProof uses real data and advanced analytics to help you make informed betting decisions. Get access to professional-grade predictions for NFL, College Football, and more.
Get Started Free